
In July 2024, a routine software update at cybersecurity company CrowdStrike spiraled into a global outage that interfered with airlines, banks, and hospitals. As businesses worldwide struggled to keep operations running, the incident made it glaringly clear that even the most sophisticated organizations aren’t immune to sudden disruption.
That’s where incident management comes in as the structured process that helps organizations stay calm under pressure and restore services fast. This guide breaks down what incident management is, why it matters, and how to put best practices into action, with monday service as the platform that turns theory into results.
Try monday serviceKey takeaways
- Incident management is the structured process that helps organizations identify, log, prioritize, and resolve issues quickly to reduce business impact.
- A clear incident management process improves accountability, speeds up recovery, and strengthens trust with customers and stakeholders.
- The incident management lifecycle provides a repeatable framework, from detection to post-incident review, promising consistency and continuous learning.
- Common challenges include alert fatigue, poor communication, and lack of visibility..
- monday service brings those best practices to life with AI-powered workflows, seamless collaboration, and a single source of truth for your incident response.
What is incident management?
Incident management is the structured process organizations use to identify, log, prioritize, and resolve incidents to restore normal service operations as quickly as possible. It creates order by giving teams a repeatable way to handle issues without wasting time or reinventing the wheel each time something goes wrong.
Incident management is realistic. It’s not about eliminating every problem, but about giving your teams the tools and processes they need to respond with confidence and protect customers as you minimize business impact.
“When incidents hit, what matters is not perfection but control. A solid incident management practice gives the organization the structure to move fast, communicate clearly, and recover services without adding chaos.” — Jose Antonio Gea Arance, IT service delivery leader
What are the primary objectives of the incident management process?
The purpose of incident management is to create a framework for teams so they can respond consistently to whatever’s thrown their way and limit disruption to the business. At its core, the process is designed to:
- Standardize response procedures by creating a clear framework for identifying, logging, and handling incidents.
- Ensure accountability by assigning ownership and responsibilities for faster, more effective resolution.
- Facilitate clear communication with a structured information flow among teams and stakeholders.
- Capture and document incidents using accurate records for tracking, auditing, and learning.
- Enable prioritization by assessing severity and impact to allocate resources appropriately.
- Support root cause analysis providing data and context for identifying long-term fixes.
- Drive continuous improvement using incident insights to strengthen processes and systems.
Why is incident management crucial for your business?
Here are the specific benefits you can expect when you commit to building an incident management plan.
Reduced downtime and disruptions
Time is money, and every minute of downtime impacts operations. With a solid incident management process, organizations can resolve issues faster and minimize service interruptions. Palo Alto Networks reports that 86% of major cyber incidents in 2024 caused downtime, reputational damage, or financial loss, underscoring the cost of a delayed response.
Improved customer trust and satisfaction
Customers judge reliability not only by uptime but also by how clearly and quickly you communicate during a crisis. Incident management offers transparency and consistency, helping users feel informed and valued. When handled well, even unexpected disruptions will reinforce confidence in your brand.
Better alignment with SLAs and compliance
Service level agreements (SLAs) and regulatory requirements demand clear response and resolution timelines. And incident management provides the structure to meet those commitments consistently. This approach also reduces the risk of penalties and keeps the organization in good standing with auditors, regulators, and partners who rely on dependable service delivery.
Lower operational costs
Without clear processes, incidents can absorb more resources and linger longer than necessary. Effective incident management avoids costly fire drills by assigning ownership quickly and reducing duplication of effort. Over time, this efficiency lowers the overall cost of IT operations and support.
Enhanced cross-team collaboration
Incidents rarely stay confined to one team, instead spanning IT, customer support, and business operations. Structured incident management creates a shared playbook, encouraging teams to communicate seamlessly and coordinate effectively. By doing so, you’ll speed up resolution when every second counts.
Greater resilience and adaptability
The real measure of incident management isn’t just how quickly you recover but how well you prepare for the next challenge. By documenting incidents and learning from them, organizations build resilience. Over time, this adaptability strengthens your systems and processes, resulting in smoother responses to future disruptions.
What is the incident management lifecycle?
The incident management lifecycle is the step-by-step framework that organizations use to handle each incident, from the moment it’s reported until lessons are learned. Key stages typically include:
- Identification and logging: You’ll detect the incident through monitoring tools, customer reports, or system alerts, and record it with all relevant details.
- Categorization and prioritization: This stage enables you to classify the incident type, such as a critical outage vs. a minor bug and rank it based on business impact and urgency.
- Triage and assignment: Based on the classification, you’ll route the incident to the right team or individual with the skills to resolve it.
- Investigation and diagnosis: The assigned team members analyze any available data, and even try to replicate the issue if necessary to determine the root cause.
- Resolution and recovery: They’ll implement a fix or workaround to restore service and verify the system is functioning normally.
- Closure: Once the incident is resolved, they’ll close the incident in the tracking system and confirm whether users are satisfied with the outcome.
- Post-incident review: The final stage should not be skipped. It involves conducting a retrospective to capture any lessons learned in your incident documentation to shape your future prevention strategies.
Incident management in different contexts
Incident management doesn’t look the same in every setting. A financial institution may focus on regulatory compliance, while a hospital would prioritize patient safety, for example. But while the specific risks shift by industry, the foundation should always be a structured, repeatable approach.
Incident management in ITIL and IT service management
In the ITIL framework, incident management is a fundamental IT service management process designed to restore normal service operations at speed. This approach is the gold standard across industries, helping IT teams reduce downtime, improve communication, and meet strict service level agreements.
“Incident management isn’t just a process. It’s the backbone of IT service continuity, resilience, and trust. Whether in cloud operations, pharma, energy, or government IT systems, the ability to respond quickly and effectively defines success.” — Lakhdar M., global IT service and incident management leader
Incident management in cybersecurity
In cybersecurity, incident management takes on a high-stakes role. Threats evolve quickly, and the cost of delay is steep. According to Palo Alto Networks, attackers exfiltrated data in under 5 hours in 25% of incidents in 2024, which was 3 times faster than in 2021. Even more alarming, in 1 in 5 cases, theft occurred in less than an hour.
Adding to the challenge, the same report finds that 70% of incidents involved attackers exploiting 3 or more attack surfaces, making response far more complex than dealing with a single breach point. Therefore, effective cybersecurity incident management requires rapid detection and response and also coordinated workflows across IT, security, and business leaders to contain damage and recover with minimal impact.
Incident management in DevOps
DevOps teams move fast, meaning incidents could arise just as quickly. Instead of treating them as disruptions, incident management becomes part of the workflow: spotting issues early, rolling back or patching as needed, and capturing lessons to improve the next release. The goal is always to keep innovation steady without sacrificing quality.
Incident management in site reliability engineering (SRE)
Site reliability engineering, or SRE, is an operations model that grew out of Google. It shifts the focus from manual, reactive work to software-driven practices that keep large systems stable.
In incident management, SRE puts heavy emphasis on learning and prevention. A single outage might trigger a blameless postmortem, or prompt engineers to add new automation that removes a weak point. Error budgets guide decisions on when to prioritize reliability over new features, making sure systems don’t tip past acceptable risk.
Incident management in customer support or service desks
In customer support, incidents can be as simple as a failed payment or as disruptive as a widespread outage. But what customers care about most is acknowledgment. Even if the fix takes time, they want confirmation that their problem has been recognized and that progress to resolve it is underway.
For service desk teams, incident management provides the guardrails. It keeps every issue documented, making sure urgent cases get the right attention, and helps agents keep customers updated while the work continues. This steady communication prevents frustration from turning into lost trust.
Incident management in healthcare and emergency response
When healthcare systems fail, the impact is immediate. A hospital that can’t access patient records, or an ambulance team cut off from dispatch means that care is delayed. And in this field, delays carry risks that no spreadsheet can capture.
That’s why healthcare and emergency response teams treat incident management as part of the core infrastructure. They rehearse scenarios the same way they train for clinical procedures, making sure handoffs are clean and communication never goes dark. Most importantly, this process gives staff the confidence to keep moving when everything around them feels unstable.
What are the challenges of incident management?
Incident management promises structure, but in practice, many teams struggle with messy realities. These are some of the most common barriers that slow resolution and increase risk.
High volume of incidents
A flood of alerts or tickets can overwhelm even large, well-established teams. When every ping looks urgent, important work slows down, and real issues risk being buried in the noise.
Alert fatigue
Constant notifications, often full of false positives, wear down attention. Over time, critical warnings start to look like background noise, until one turns out to be real and it’s too late.
Poor categorization
Without clear severity levels, teams waste hours debating what matters most. Resources end up chasing small issues while more damaging ones wait in the queue.
Siloed communication
When operations, IT, and support use different tools or workflows, updates are lost. Lack of coordination can double response times and leave customers in the dark.
Inconsistent processes
Ad hoc fixes feel faster in the moment, but they create unpredictable outcomes. One incident might be resolved quickly, while a nearly identical one drags on because the team needs to start from scratch.
Limited visibility
Fragmented tools mean no one has a full picture of what’s happening. Teams lose time piecing information together, and decisions are made without context.
Lack of skilled resources
Some incidents demand expertise that isn’t available in-house. Without specialists ready to respond, organizations scramble to plug the gap, which slows recovery and increases costs.
Bad KPI selection
Metrics like mean time to resolution (MTTR) or ticket volume are useful but incomplete. If they aren’t tied to business outcomes, leaders can’t see whether incident management is truly improving resilience.
Rushed responses
A rushed response may fix one issue but create two more. Teams walk a fine line between acting fast and ensuring the solution holds.
Essential incident management tools
Good processes only work when they’re backed by the right technology. The following tools form the backbone of modern incident management.
- Incident tracking: A central system to log, assign, and monitor incidents keeps everything organized. Without it, teams risk duplicating effort or losing sight of open issues.
- Virtual agents: AI-powered assistants handle routine queries or ticket intake, reducing the pressure on human teams and speeding up first responses.
- AIOps: By analyzing huge volumes of operational data, AIOps platforms can spot anomalies early and recommend likely fixes, often before customers even notice an issue.
- Chat room: A dedicated chat space keeps everyone in the loop. It cuts down on email chains and prevents fragmented communication.
- Video chat: For complex, high-stakes issues, video calls allow faster collaboration. Engineers can talk through solutions in real time instead of waiting on written updates.
- System alerts: Automated alerts flag problems as soon as they occur, making sure no one has to rely on manual checks to spot an outage or slowdown.
- Documentation tool: During or after an incident, a good documentation system captures the timeline, actions taken, and outcomes for future reference.
- Notification and escalation tools: First responders can’t solve every issue. Instead, escalation tools move urgent incidents to the right person or team without delay.
- Knowledge base and runbook automation: Pre-written guides and automated playbooks give teams a clear path when common problems occur. Instead of starting from zero, responders can lean on knowledge management to follow proven steps.
Revolutionize incident management with monday service
Most teams juggle tickets, alerts, and cross-department updates in a patchwork of tools that isn’t pretty. The result is slow resolution times, missed handoffs, and frustrated customers.
monday service changes that with a dedicated service platform connecting every moving part of your organization, from ticket intake to SLA tracking, in one intuitive place.
Instead of forcing teams to adapt to rigid incident management software, monday service adapts to you. With no-code customization, embedded AI, and seamless integrations, it brings clarity to chaotic moments and speeds up resolution without adding complexity. Whether you’re handling IT incidents, customer escalations, or company-wide service requests, monday service gives you the structure and flexibility to respond with confidence. Here’s what you’ll achieve.
Resolve incidents faster with smart escalation workflows
When issues intensify or repeat, avoid manual rerouting. With monday service, you can automatically escalate incidents using the linked “Incidents” boards, complete with status, ownership, linked tickets, and post-incident documentation, all managed through structured columns and automations.
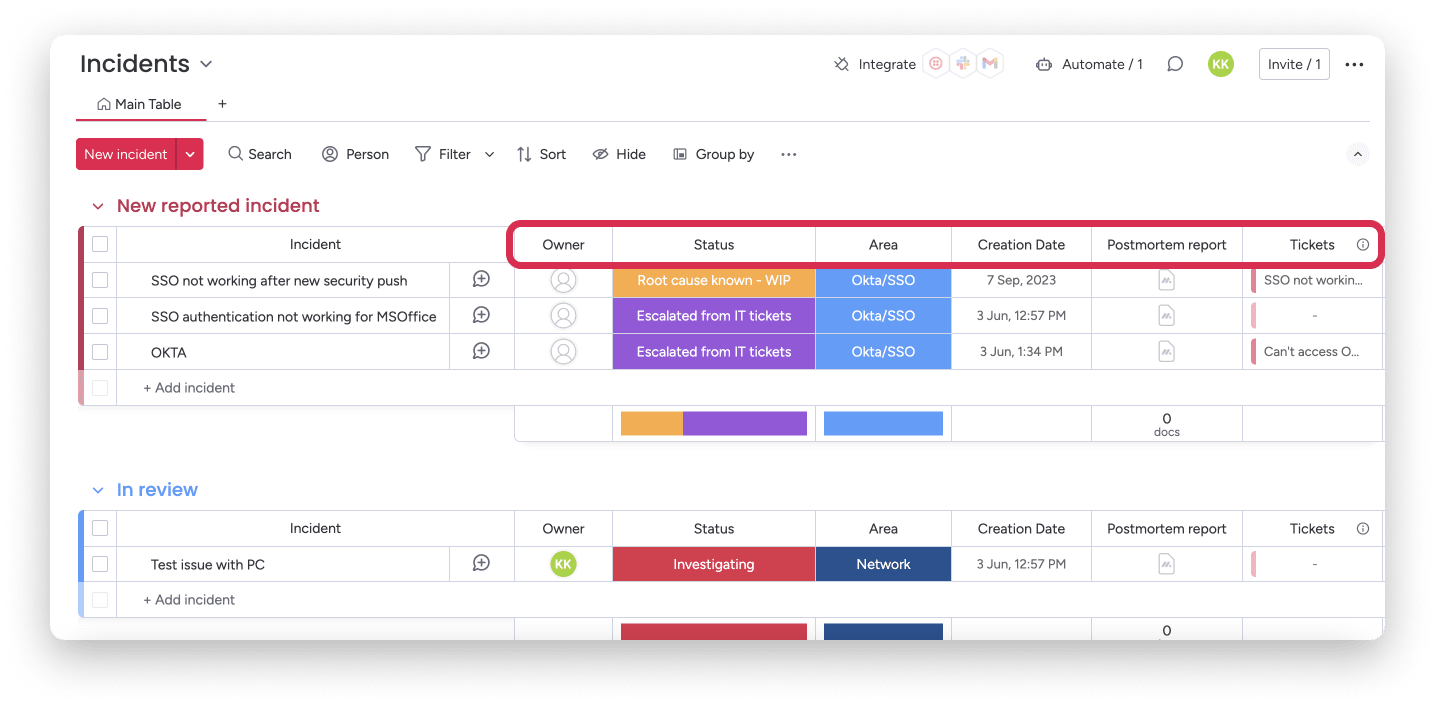
Capture resolution insights effortlessly with post-incident reporting
Learn and prevent recurrence using standardized postmortem documentation. Upload consistent reports directly into each incident item, using templates and dynamic fields like incident name or resolution time to streamline reporting and institutional learning.
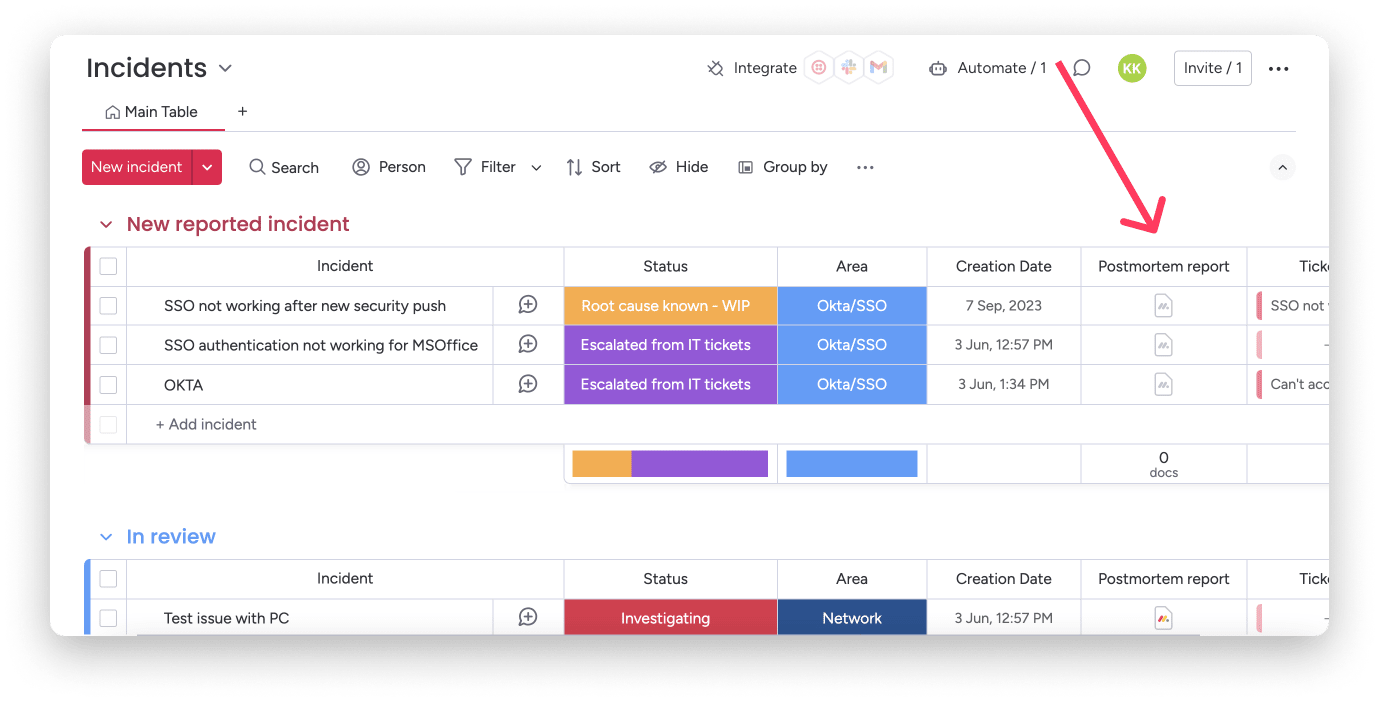
Stay on top of SLAs with intelligent alerts and automations
Never miss a deadline again. With monday service smart automations, you can trigger alerts when SLAs are near breach, pause or update timers, and automatically move items between groups based on status changes, so your team stays proactive and compliant.
Empower faster responses with AI-powered ticket routing and classification
Speed up triage and focus on high-impact issues. monday service’s AI assistant categorizes new tickets by urgency, sentiment, or type, and uses smart routing to assign them to the right teams automatically, reducing manual handoffs and accelerating resolution.
Boost speed and accuracy with always-on digital workforce
AI is a critical partner in modern incident management. With monday.com’s Digital Workers, agentic AI proactively corrects or triggers workflows without waiting for human input. This reduces response times by freeing your team to focus on complex, high-value incidents.

Centralize all service intake in one seamless customer portal
Create a smoother experience for end users and support teams alike. With the customer portal, users can submit requests, view ticket status, access self-service content, and follow up, all through a fully branded, external-facing service portal that acts as a single source of truth.
Try monday service7 best practices in incident management
Best practices are what turn incident management from a reactive scramble into a steady, repeatable process. These guidelines keep teams focused under pressure so you can capture lessons that make the next response stronger.
1. Create a clear incident response plan
An incident response plan removes guesswork when the pressure is on. By defining roles, responsibilities, and workflows ahead of time, teams know exactly who does what and how decisions get made. IT service delivery leader, Jose Antonio Gea Arance’s top tip is to:
Appoint a strong Major Incident Manager: someone with calm under pressure, clear communication, and authority to make decisions. This role can make the difference between controlled resolution and complete chaos.
2. Establish a single source of truth
The best place to store your incident response plan? A central, secure location like monday service, which acts as your source of truth. Instead of hunting through files or email threads, teams can access the plan, track live incidents, and update documentation in one place. Shared visibility removes confusion and keeps everyone on the same page when speed matters most.
3. Set up real-time communication channels
When incidents strike, real-time tools like chat, automated alerts, or public status pages give teams and stakeholders the updates they need, the moment they need them. With open communication, trust builds and resolution moves faster.
4. Reduce manual work and human error
Manual triage and routing waste precious time and increase the risk of mistakes. Tools like AIOps, virtual agents, and automated escalation handle repetitive tasks in the background, so incidents are categorized, assigned, and acted on without delay.
5. Practice regular incident simulations
Plans look perfect on paper, until they’re tested. Running simulations gives teams a safe way to rehearse responses and uncover any weak spots. It’s also a great way to build confidence under pressure. The more familiar people are with the process, the less likely panic will take over when a real incident hits.
6. Integrate monitoring with response
Linking performance monitoring tools directly to your workflows means critical signals are escalated and triaged without delay. That connection turns raw data into meaningful, timely responses.
7. Measure and refine continuously
Incident management gets sharper with every round of measurement and refinement. So, KPIs like MTTR, SLA compliance, or incident volume by type reveal how well your processes perform. Tracking them over time exposes bottlenecks and shows whether changes are making the desired impact.
Turn incident management best practices into results with monday service
Every organization faces incidents, but it’s how you respond that defines the outcome. With the right processes, tools, and mindset, challenges become opportunities to build trust and resilience. monday service brings those best practices to life in one intuitive platform, combining ticketing systems, communication, analytics, and AI-powered automation. The result? Faster resolutions, clearer accountability, and a calmer, more confident response to whatever comes your way.
Keep your incident management under control by getting a free trial of monday service.
Try monday serviceFAQs about incident management
What is the National Incident Management System?
The National Incident Management System (NIMS) is a standardized framework developed by FEMA in the United States. It provides a consistent approach for government agencies, businesses, and nonprofits to work together during emergencies. By defining roles, processes, and communication protocols, NIMS helps organizations coordinate effectively during incidents of all scales.
What is the difference between incident management and problem management?
Incident management focuses on restoring normal service as quickly as possible when disruptions occur. Problem management, on the other hand, digs deeper into the underlying causes of recurring incidents. Both are core ITIL practices but serve different goals.
How does a well-defined incident management process benefit a business?
A well-defined incident management process minimizes downtime, reduces costs, and ensures consistent communication with customers and stakeholders. Businesses that follow structured practices recover faster, maintain compliance with SLAs, and improve customer trust. Over time, clear processes also provide data for continuous improvement and better decision-making around resource allocation.
What are some key performance indicators (KPIs) for incident management?
Common KPIs for incident management include:
- MTTR (Mean Time to Resolution) is the average time taken to restore service
- Incident volume by category or severity identifies trends
- SLA compliance rate is the percentage of incidents resolved within agreed targets
- First contact resolution raterefers to incidents solved without escalation.
What is the legal responsibility of management regarding incidents?
Management holds a duty of care to protect business operations, employees, and customers during incidents. Legal responsibilities often include complying with industry regulations, documenting responses, reporting breaches or outages, and ensuring timely communication. Failure to meet these obligations can result in fines, reputational damage, or even litigation, depending on the jurisdiction.
Can a small business benefit from using incident management software?
Yes. Small businesses often lack large IT teams, making efficient incident management even more critical. Software centralizes reporting, automates responses, and ensures nothing slips through the cracks. It also helps small businesses maintain compliance, improve customer satisfaction, and scale processes as they grow, without adding heavy administrative overhead.
What's the difference between an operational incident management plan and a resource allocation plan?
An operational incident management plan outlines how an organization responds to disruptions, including roles, escalation paths, and communication procedures. A resource allocation plan, by contrast, defines how people, tools, and budgets are distributed to support incident response. The first is about process execution, the second about capacity planning.
What is an incident management framework?
An incident management framework is a structured set of policies, processes, and tools designed to guide how incidents are detected, reported, escalated, and resolved. Frameworks like ITIL, COBIT, or ISO 20000 provide best practices that organizations can adapt to their specific needs.