
IT teams manage rising demand across hybrid work, expanding infrastructure, and higher expectations for fast, reliable support. Ticket volumes grow as more services move to the cloud, and organizations depend on the service desk to keep employees productive and systems running.
Strong ITSM practices give teams the structure needed to stay organized and responsive. Clear workflows, ownership, and consistent service patterns help leaders scale support across departments and adapt to shifting priorities.
Automation and AI now strengthen these foundations. These capabilities classify and route work, reduce manual effort, and help service teams handle fluctuating demand with more predictable operations.
This guide covers the practices that matter most in 2026, including incident, request, and problem workflows, change and knowledge management, hybrid cloud operations, and modern implementation strategies. It also outlines how monday service supports these workflows in one connected platform for tickets, projects, knowledge, and automation.
Key takeaways
- Strong ITSM practices move teams from reactive work to reliable service delivery tied to business goals
- Automation and AI shorten resolution times, improve consistency, and allow agents to focus on higher-value tasks
- Effective change and knowledge management reduce risk and support fast, stable delivery
- Successful ITSM implementations focus on adoption, no-code customization, and quick time to value
- monday service brings ticketing, project work, knowledge, automation, and analytics into one platform so teams can apply ITSM best practices at scale
What is ITSM, and why do best practices still matter in 2026?
IT service management (ITSM) covers the work involved in designing, delivering, operating, and improving IT services. While a help desk focuses on ticket intake and resolution, ITSM spans the full service lifecycle, from planning new services to supporting and optimizing existing ones.
ITIL (Information Technology Infrastructure Library) provides guidance for many of these processes, including incident, change, and problem management. ITSM brings this guidance into daily operations through tasks such as triaging requests, approving changes, maintaining the service catalog, and tracking SLAs (service level agreements).
Effective ITSM leads to outcomes that matter to the business:
- Reliable services that keep teams productive
- Consistent experiences that reduce confusion and support costs
- Strong risk management that limits outages and security issues
- Service delivery aligned with organizational goals
ITSM practices now reach well beyond IT. HR teams manage onboarding and employee requests. Facilities teams coordinate maintenance and space planning. Finance teams run procurement and approvals. Structured workflows, service catalogs, and knowledge programs support all of these functions.
Why best practices evolve with technology and expectations
Technology shifts and user expectations continue to change how service teams work. Hybrid work, cloud adoption, and rapid SaaS growth introduce new dependencies that require more visibility and coordination across systems.
Employees look for clear request paths, helpful self-service options, and real-time updates. These expectations shape the best practices that matter most in 2026. Automation supports more core workflows. Data helps teams understand patterns, predict demand, and improve outcomes. Enterprise service management expands as more departments adopt consistent intake and workflow structures.
As organizations scale, ITSM best practices become a strategic investment that strengthens service quality, improves agility, and supports the evolving needs of a modern enterprise.
ITSM maturity model: where teams start and where they can progress
Organizations typically move through recognizable stages as their ITSM practice develops. Each stage builds operational clarity, increases service consistency, and expands the ability to support the business.
- Level 1: Ad hoc: Basic ticketing with inconsistent processes. Work is reactive and handled case-by-case.
- Level 2: Standardized: Defined workflows, SLAs, structured intake, and straightforward reporting across core services.
- Level 3: Scalable: Automation supports high-volume tasks, knowledge articles stay current, and change processes follow a consistent model.
- Level 4: Optimized: AI-assisted operations, enterprise service management across departments, hybrid cloud governance, and real-time analytics anchor decision-making.
This framework gives teams a simple reference point to assess where they are today and set realistic goals for future improvements.
Core ITSM best practices every service leader should prioritize
A strong ITSM foundation supports reliable, scalable service delivery across the organization. These practices help teams manage growth, reduce risk, and deliver consistent experiences across varied environments.
Align IT strategy with business goals
ITSM has the most impact when services directly support business priorities.
Best practices:
- Maintain a service portfolio mapped to clear business outcomes
- Include stakeholders in setting service priorities, SLAs, and improvement plans
- Share service performance metrics to guide decisions and highlight impact
Standardize key ITSM processes around clear workflows
Defined ITSM processes help teams work more efficiently, reduce ambiguity, and facilitate automation across the service desk.
Best practices:
- Document responsibilities, approval paths, and core steps
- Set SLAs and OLAs that reflect day-to-day operations
- Use consistent categories and priority rules to improve routing
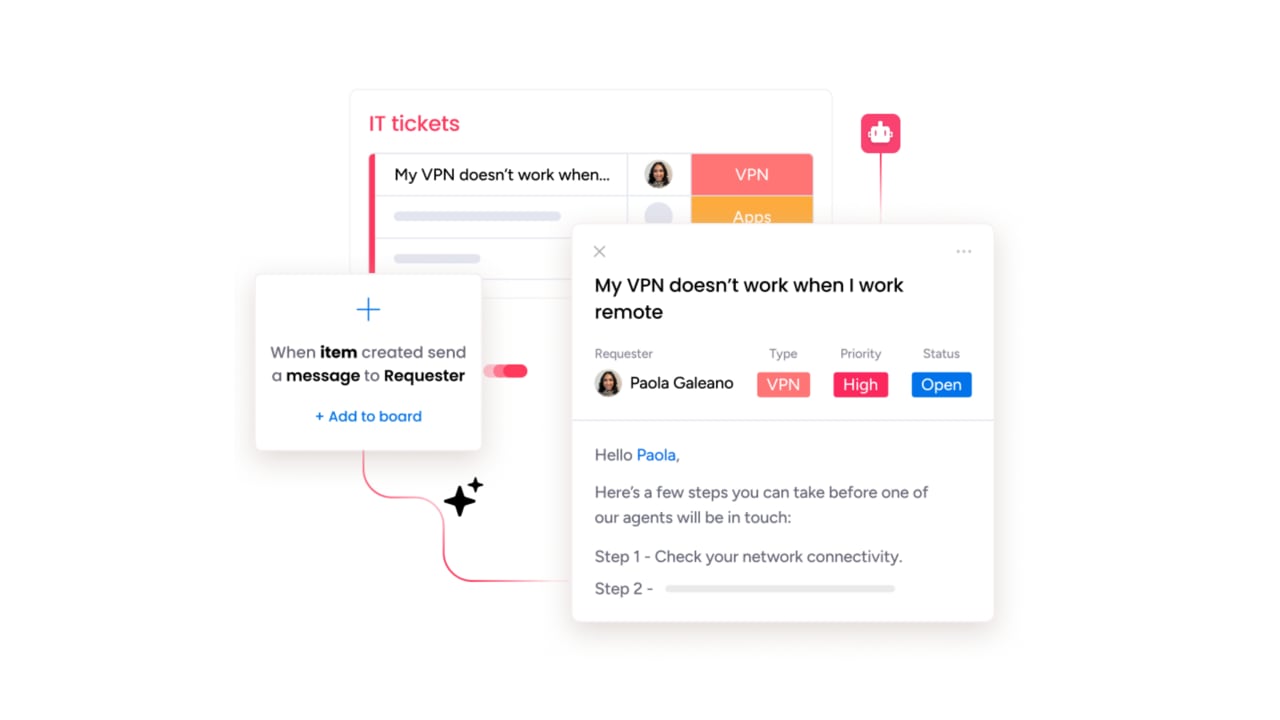
Develop a clear and accessible service catalog
A structured service catalog helps employees request support through predictable, well-defined paths.
Best practices:
- Create catalog items with predefined fulfillment steps
- Write descriptions and expectations in straightforward language
- Update catalog entries as applications and team structures evolve
Track meaningful metrics and KPIs
KPIs help teams measure performance, identify patterns, and communicate IT’s value.
Best practices:
- Track MTTR, first-contact resolution, SLA performance, and request volume
- Monitor trends such as repeat incidents and peak periods
- Share dashboards with leadership to support planning and transparency
Build a culture of continual improvement
High-performing service teams refine processes regularly and maintain clear ownership.
Best practices:
- Hold structured reviews after major incidents or changes
- Keep an improvement backlog with owners and measurable outcomes
- Connect improvements to tickets, projects, and reporting within one platform
How to streamline service delivery with incident, problem, and request management
Incident, problem, and request management form the backbone of daily ITSM work. Clear workflows and accurate data help teams move from intake to resolution with speed and consistency.
Incident management best practices
Incident management restores service quickly and keeps users informed while work is in progress.
Best practices:
- Offer clear intake channels through portal, email, chat, or phone
- Prioritize incidents based on impact and urgency
- Establish escalation paths and communication steps for each severity level
- Link incidents to related assets, projects, or user records
- Track progress across teams and identify blockers early
How automation supports incident management
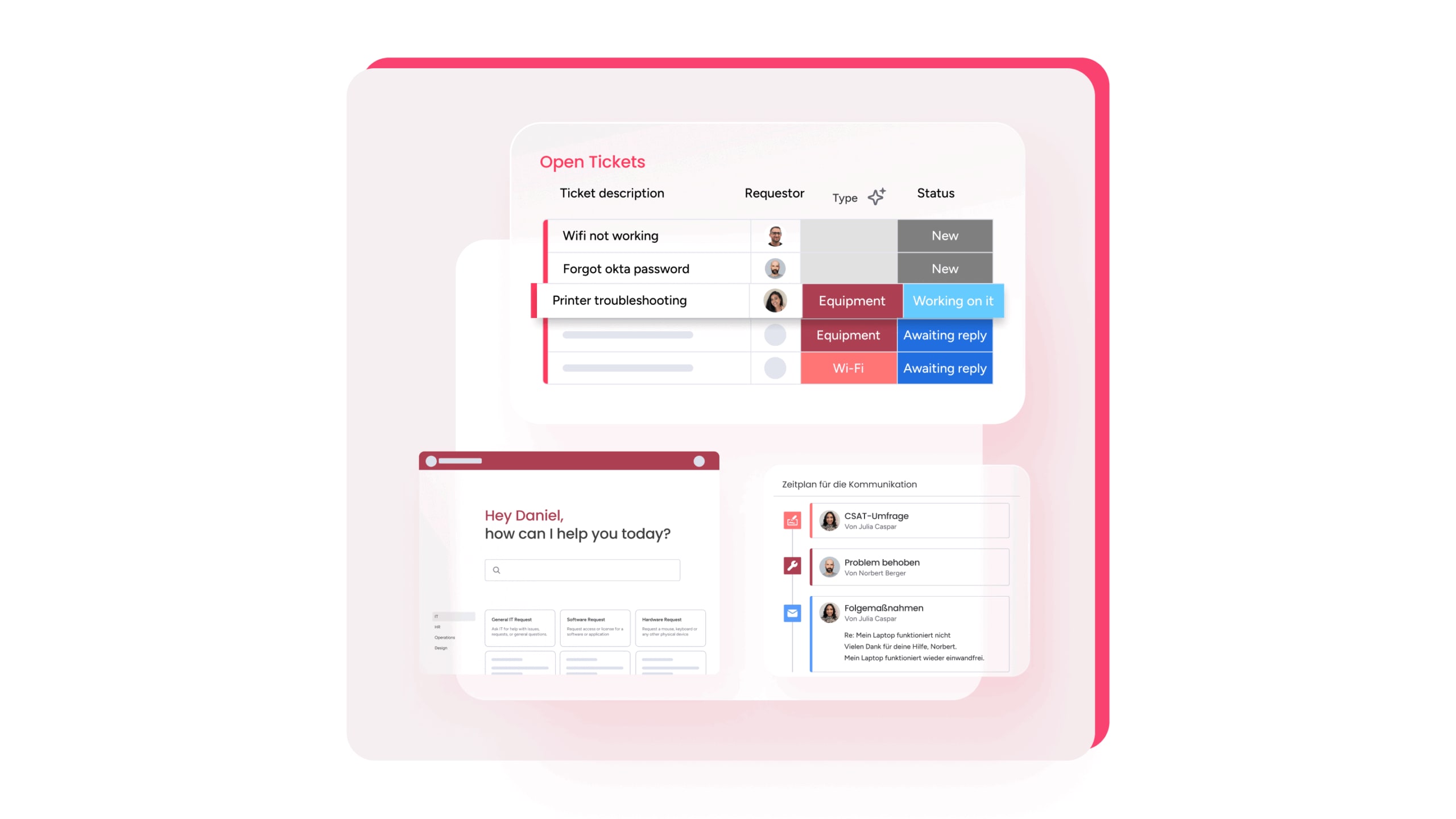
Automation strengthens response speed and accuracy at scale.
- Classify new incidents with AI Blocks
- Route tickets based on skills, capacity, and location
- Trigger updates, SLA alerts, and escalations automatically
- Generate summaries so agents review long threads quickly
What’s the difference between incident and problem management?
Incident and problem management serve different objectives. Clear separation helps teams assign work correctly and reduce recurrence.
Incident management focuses on:
- Restoring service as quickly as possible
- Applying known fixes and workarounds
- Keeping users informed until service is restored
Problem management focuses on:
- Identifying underlying causes
- Analyzing trends across related incidents
- Recommending long-term remediation
Known Error Database (KEDB):
- Stores confirmed root causes and validated workarounds
- Enables faster resolution for issues without an immediate fix
Problem management and the role of a KEDB
Problem management improves long-term service reliability by revealing patterns and reducing repeat incidents.
Best practices:
- Link related incidents to a problem record
- Maintain a KEDB with known errors and workarounds
- Document root cause analyses and share findings with stakeholders
- Partner with engineering and development teams on permanent fixes
Request management best practices
Requests cover planned, predictable work such as access changes, hardware orders, and software installations. Treating them separately from incidents helps teams forecast demand and gives users clearer expectations.
Key practices:
- Define which items count as service requests
- Standardize common requests as service catalog items with clear steps and owners
- Publish target fulfillment times
- Track request volume and categories to guide staffing and procurement
- Automate approvals and fulfillment steps when the workflow is predictable
This structure allows teams to move routine work efficiently while dedicating more time to complex investigations and escalations.
ITSM change management best practices in a high-velocity world
Modern development cycles move quickly. Change management supports that pace with clear structure, predictable workflows, and governance that scales without slowing delivery. The goal is to reduce risk, keep teams aligned, and maintain operational stability across cloud, on-prem, and hybrid environments.
Define clear change types and risk levels
Simple classification strengthens consistency and speeds the approval process.
Standard changes
- Low-risk, repeatable activities
- Follow predefined templates and documented steps
- Pre-approved without individual review
Normal changes
- Medium or high risk
- Require assessment, testing, and appropriate approvals
- Use structured workflows and clear ownership
Emergency changes
- Urgent fixes tied to security, availability, or compliance
- Use an expedited process with mandatory post-review
- Maintain essential documentation
Maintain essential documentation
Documentation gives teams a shared reference point and reduces coordination gaps.
Key practices:
- Keep a shared change calendar to prevent conflicting deployments
- Record change details, testing results, and approval paths
- Capture updates to dependencies and configuration data
Core principles of effective change management
- Apply risk-based approval paths so oversight matches potential impact
- Keep CAB reviews focused and data-driven
- Capture required documentation for audit and knowledge retention
- Use post-implementation reviews to refine processes and surface lessons
What a lightweight CAB process looks like
High-velocity environments benefit from reviewing exceptions rather than every request.
Characteristics of a lightweight CAB:
- Short, structured weekly sessions (15–20 minutes)
- Pre-CAB scoring so low-risk changes auto-approve
- Asynchronous input from development, operations, and security
- Clear criteria for what must be reviewed
This model maintains effective oversight without creating delays.
How to prevent change management from becoming a bottleneck
- Use standardized templates to reduce back-and-forth
- Set time-boxed decision windows, typically 24–48 hours
- Automate approvals, notifications, and communication steps
- Let low-risk, repetitive updates skip CAB and move straight to execution
These steps move work forward while maintaining guardrails.
Include security and compliance without slowing work
Security and compliance teams can participate through integrated workflows instead of manual checkpoints.
Effective practices include:
- Assigning a high-risk security review to a designated reviewer
- Embedding compliance checks as required fields
- Standardizing governance rules inside the platform
- Giving security visibility through dashboards rather than manual sign-offs
This approach maintains audit readiness and operational speed.
Automate approval workflows without losing control
Automation helps route changes to the right reviewers and maintain consistent governance.
Capabilities include:
- Routing based on change type, system, or risk level
- Capturing approvals through connected tools such as DocuSign
- Logging all artifacts, test results, and approvals in one system of record
Automation removes manual tracking without reducing oversight.
Implement data-driven change authorization and rollback plans
Historical data improves planning and risk scoring.
Key practices:
- Analyze past failures to refine risk levels
- Monitor incident patterns after deployments
- Set clear success criteria before rollout
- Establish rollback triggers tied to measurable thresholds
- Link change records to incidents, problems, and assets
- Maintain documented backout plans for all non-standard changes
These steps help teams act quickly and confidently during deployments.
Human-centered change management that drives adoption
Change processes succeed when people understand how the workflow operates and why each step matters.
Strong approaches include:
- Defining clear roles such as service owner, process owner, and knowledge manager
- Communicating upcoming changes early and concisely
- Running pilots that build confidence before wider rollout
- Offering practical, workflow-aligned training
- Gathering feedback from agents and iterating based on real usage
People adopt processes more readily when they feel informed, supported, and involved.
ITSM knowledge management best practices that actually reduce tickets
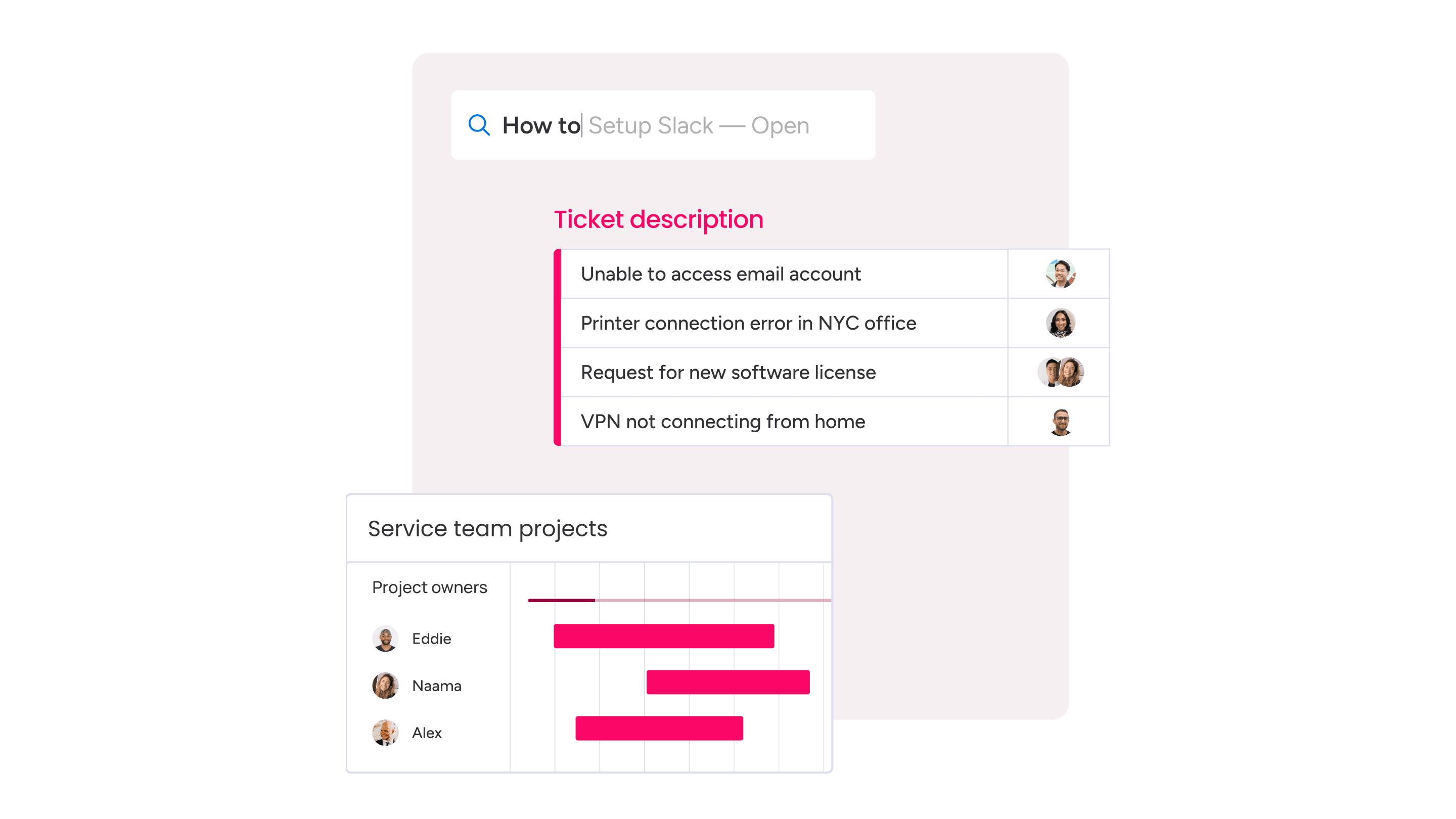
A strong knowledge program gives users fast answers and gives service teams more time for higher-value work. When articles are accurate, easy to find, and embedded in daily workflows, teams resolve issues faster and rely less on manual handoffs. AI strengthens this foundation with tools that keep content current.
Design knowledge with users and agents in mind
Articles perform best when they follow a consistent structure and reflect how people search for help. Clear ownership and regular reviews keep content reliable and actionable.
Best practices:
- Use templates that outline symptoms, steps, and visuals
- Assign article owners and set scheduled review cycles
- Tag content with standardized categories and search terms
- Improve discovery with keyword variations and structured metadata
- Collect feedback to guide revisions and highlight unclear entries
These habits keep the knowledge base relevant as systems and workflows change.
Build a self-service portal and AI-supported knowledge base

Self-service reduces ticket volume and helps users resolve common questions quickly. AI expands reach and improves how users and agents interact with knowledge.
Core benefits:
- Faster resolution for routine questions
- Fewer repetitive tickets
- Greater consistency across teams
AI adds:
- Article recommendations based on a user’s question or ticket text
- Summaries of long or technical content
- Flags for outdated or low-performing articles
Knowledge boards in monday service track ownership, approvals, review cycles, and article status. AI Blocks help refine content and keep information aligned with current processes. A customer portal will bring these capabilities directly to end users.
Embed knowledge into daily workflows
Knowledge works best when it appears in context. Agents should be able to use, reference, and update content without switching tools or copying information across systems.
Effective embedded knowledge includes:
- Attaching articles directly to tickets
- Suggesting new articles when agents spot recurring patterns
- Leveraging documented steps during escalations
- Triggering content updates when products or systems change
- Identifying outdated articles through usage patterns and feedback
- Recommending relevant articles automatically when agents open new tickets
Embedding knowledge this way helps teams maintain consistency and resolve issues with fewer manual steps.
Example: knowledge management in action
Agents submit article drafts to a Knowledge board. Reviewers approve updates. Automations publish entries and archive outdated versions. AI Blocks summarize changes so content remains accurate and easy to follow.
How should you measure ITSM success and drive continual improvement
Strong ITSM programs depend on reliable data. Metrics help teams understand service performance, pinpoint constraints, and identify improvements that will have the highest impact. A clear measurement approach also helps IT leaders articulate value and guide long-term planning.
Focus on KPIs that link to business value
KPIs are most useful when they highlight how well IT supports the organization. These metrics reflect service quality, operational efficiency, and the experience employees have when they request support.
Examples of meaningful ITSM metrics:
- First response time, overall resolution time, and SLA compliance
- Ticket volume and patterns (grouped by service, business unit, or channel)
- Change success rate and the impact of failed changes
- Knowledge article usage and how often users resolve issues through self-service
- User satisfaction scores, such as CSAT or internal NPS
A balanced KPI set helps teams see strengths clearly and identify where processes need refinement.
Use real-time analytics to move from reactive to proactive
Dashboards give leaders an immediate view of performance. Trends reveal where demand is rising, where workflows slow down, and where improvements will make the biggest difference.
Analytics can:
- Surface recurring issues, hot spots, and service disruptions
- Highlight overextended teams or individuals
- Predict peak periods and upcoming capacity needs
Within monday service, analytics combine service metrics with project timelines and resource data. This unified view supports confident decisions about improvements, staffing adjustments, and roadmap priorities.
How can you extend ITSM best practices across the enterprise
Many departments manage structured requests, approvals, and communication cycles. ITSM provides a clear model they can use to standardize work, reduce delays, and create consistent experiences for employees. Expanding these practices strengthens alignment across the organization.
Apply ITSM methodologies to HR, facilities, and more
Non-IT teams often run service-like processes. ITSM workflows help them handle requests with greater structure and predictability.
Examples of common ESM use cases:
- HR handling onboarding, offboarding, and employee lifecycle requests
- Facilities managing maintenance, repairs, and space planning
- Finance running approvals, procurement cycles, and policy-driven workflows
Best practices for extending ITSM across departments include:
- Reusing ITSM workflows with terminology adjusted for each team
- Creating consistent standards for intake, approvals, fulfillment, and communication
- Centralizing documentation and knowledge so employees know where to find answers
This approach strengthens operational clarity while supporting each department’s unique needs.
Use one platform for cross-department collaboration
Service workflows often span multiple teams. A shared platform helps departments coordinate work, resolve handoffs smoothly, and maintain consistent communication.
Benefits of a shared service platform:
- Visibility into requests, projects, and priorities across teams
- Coordinated collaboration on multi-step or multi-owner work
- Shared reporting and insights for leadership
Within monday service, IT, HR, facilities, finance, and other internal groups work from a shared environment. Ticketing, project work, and knowledge live together, supported by integrations such as CRM tools, directories, and asset systems. This gives each team the context they need to act quickly and deliver reliable service.
ITSM best practices for hybrid cloud and complex environments
Hybrid and multi-cloud environments create new operational demands. Services run across on-prem systems, multiple clouds, and SaaS platforms. ITSM best practices give teams the structure to manage this complexity with clear workflows, reliable data, and consistent execution.
Understanding the unique challenges of hybrid cloud ITSM
Modern environments span several hosting models, which introduce challenges such as:
- Infrastructure is distributed across multiple environments
- Complex asset and configuration tracking
- Tool stacks from several vendors that depend on reliable integrations
- Visibility gaps across monitoring and observability tools
- Layered security and compliance requirements
Accurate configuration data is critical. A focused CMDB helps teams understand relationships, manage dependencies, and reduce operational risk.
Best practices include:
- Using a CMDB or “CMDB-lite” that captures essential relationships
- Connecting services to infrastructure across cloud, on-prem, and SaaS systems
- Linking configuration data to tickets, problems, and changes
- Automating discovery and relationship mapping
- Auditing configuration data after migrations or major updates
Governance and security considerations
Hybrid environments require governance that scales across systems and security models.
Key practices include:
- Defining access controls, approval steps, and data-handling standards
- Aligning ITSM workflows to compliance requirements
- Applying approval paths that adapt to the risk level
These practices help teams maintain auditability and consistency as infrastructure expands and changes over time.
Automation and AI in ITSM: Building a future-ready service desk
Automation and AI help service teams move faster, reduce manual work, and deliver more predictable operations. When routine activities run in the background, agents spend more time on complex issues and cross-team collaboration.
How can automation improve ITSM service desk efficiency
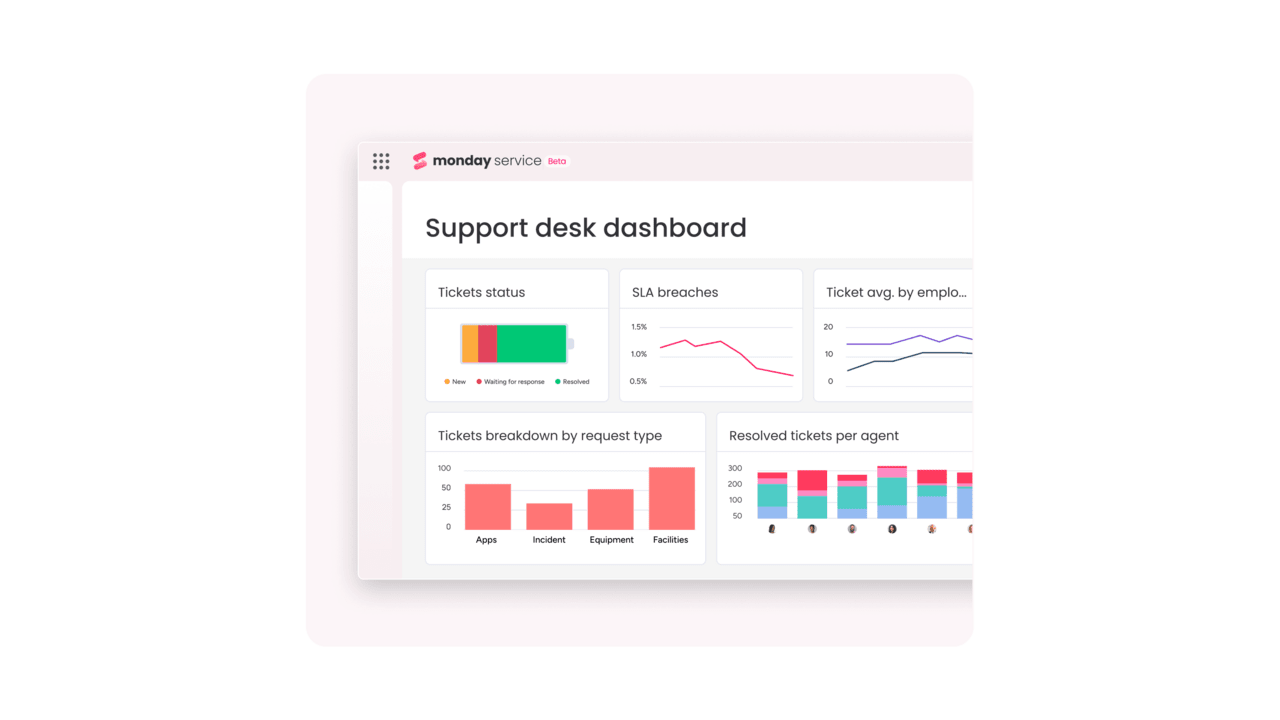
Automation supports high-volume tasks and reduces manual steps across the service lifecycle.
High-impact automations include:
- Automated triage, categorization, and routing
- Immediate status updates and notifications
- SLA tracking with time-based alerts
- Escalations triggered on complexity, urgency, or workload
- Automatic retrieval of data from integrated systems
- Bulk updates or workflow actions across related tickets
These capabilities help teams maintain service quality as demand fluctuates.
What role does AI play in modern ITSM?
AI in ITSM adds context, prediction, and pattern recognition on top of automation. It helps teams interpret requests, identify trends, and make faster decisions.
Core capabilities include:
- Predicting incident trends before they surface
- Recommending solutions based on resolved tickets
- Summarizing long threads into actionable information
- Detecting sentiment in user messages
- Suggesting next steps or potential workarounds
- Managing high ticket volumes without expanding headcount
- Producing personalized responses at scale
These capabilities help teams stay responsive, even in complex environments.
How monday service’s AI pieces work together in one workflow
Each AI capability contributes to a different part of service operations.
AI Blocks (board-level actions):
- Categorize tickets
- Summarize long threads
- Extract key fields from user messages
Product Power-ups (packaged AI capabilities):
- AI-driven routing rules
- Sentiment detection
- Classification models trained on your historical data
Digital Workers (cross-board automation):
- AI Service Agent handles routine requests
- Service Tracker monitors patterns, flags issues, and generates summaries
This combination creates an end-to-end workflow that adapts to volume, urgency, and user needs.
How AI will shape the role of IT service agents by 2026
As AI takes on repetitive work, agents focus on responsibilities that require judgment, coordination, and deeper analysis.
Key areas of focus:
- Investigating complex issues that span teams
- Completing root cause analysis and long-term remediation
- Managing escalations
- Communicating during high-impact incidents
- Improving knowledge assets
- Leading workflow and process improvements
- Collaborating with development, security, and operations on systemic issues
AI manages scale; agents drive service quality and strategic improvement.
Implementation strategies for ITSM tools that stick
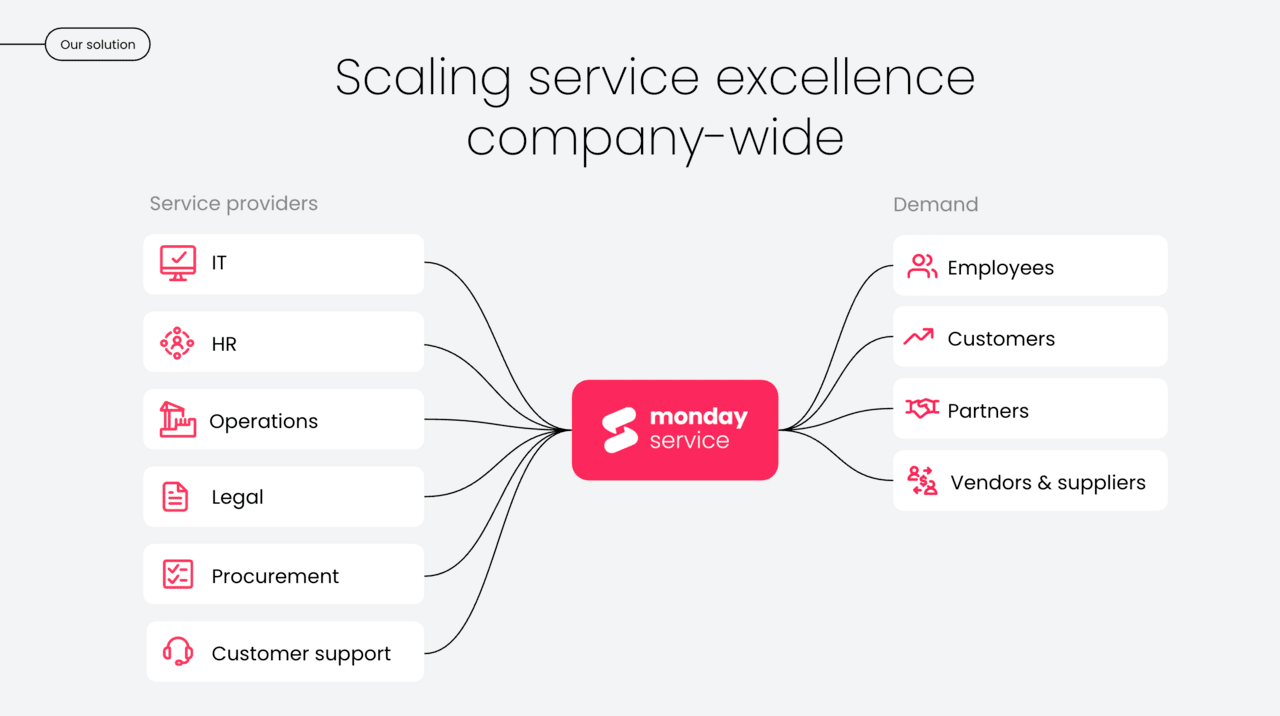
Solid ITSM implementations balance structure with flexibility. Teams see the most impact when rollout feels simple, adoption happens quickly, and the system can grow without heavy configuration work. No-code tools, clear workflows, and automation support that kind of long-term agility.
Learnings from ServiceNow and other leading ITSM systems
Enterprise ITSM platforms shaped how organizations formalize their service operations. They also revealed where teams tend to struggle once the system grows.
Common challenges teams encounter include:
- Configurations that expand over time and require dedicated administrators
- Interfaces that slow adoption for agents and business users
- Long implementation cycles are tied to deep customization
- High maintenance costs and ongoing overhead
Modern teams adjust their approach to avoid these pitfalls. They begin with ready-made workflows, streamline the experience for agents, limit custom builds, establish data governance early, and apply advanced capabilities only after core processes run smoothly. This mindset creates a system that evolves without adding unnecessary complexity.
What we’ve learned from mature ServiceNow implementations
Large ServiceNow environments offer clear lessons about what promotes stability over time. Teams that avoid long-term friction take steps such as:
- Staying close to out-of-the-box functionality
- Using the platform as a system of record rather than a collaboration hub
- Pairing it with complementary tools for project work and cross-functional planning
- Applying strict change controls for configuration updates
- Automating tasks only when inputs and outputs stay consistent
These patterns help organizations maintain reliability while reducing administrative overhead.
Practical steps to implement or upgrade your ITSM system
A focused rollout builds momentum and helps teams adopt new workflows with confidence.
Recommended steps include:
- Aligning scope and success metrics with stakeholders
- Mapping current processes to uncover friction points
- Selecting a platform with no-code customization, automation, and unified analytics
- Starting with one or two high-impact processes, such as incident or request management
- Providing onboarding that reflects real workflows
- Refining configurations based on early usage signals
This approach delivers value early while shaping the system around actual operational needs.
Why ease of use and no-code customization matter
Teams adapt faster when they can modify workflows without developer support. No-code capabilities make continuous improvement practical for service leaders.
Benefits include:
- Updating workflows in minutes
- Modifying automations as processes evolve
- Responding to agent feedback quickly
- Improving operations without waiting on release cycles
The monday service platform supports this with best-practice templates, no-code automations, AI Blocks, and a flexible structure that keeps maintenance simple.
How monday service brings ITSM best practices to life
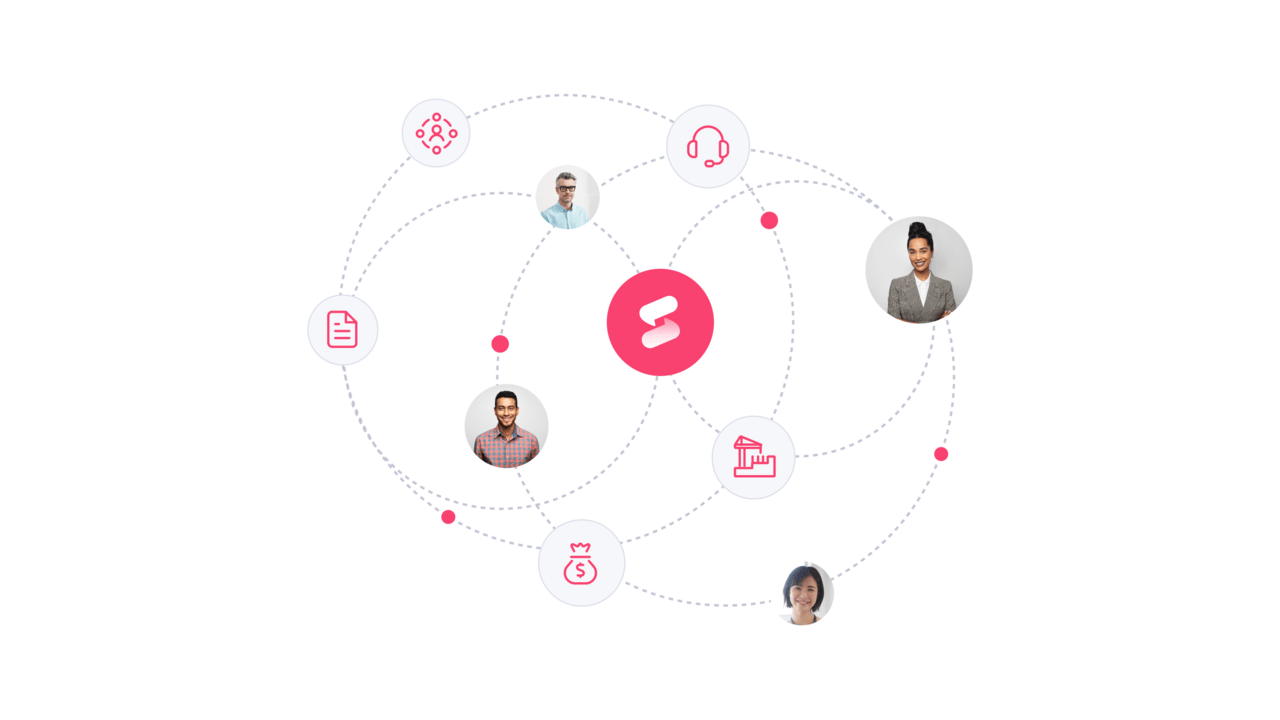
Modern service teams work best when ticketing, knowledge, projects, and automation live in a single environment. monday service combines these elements so teams can operate with clarity and scale without added complexity.
Holistic service management — unify tickets, projects, and teams
Work moves faster when teams share the same system for intake, execution, and communication.
Key capabilities include:
- Centralized ticketing with SLA configurations
- A configurable service catalog with structured request workflows
- Knowledge management boards for articles, reviews, and documentation
- Multi-channel intake from email, Gmail, Outlook, and Slack (with a customer portal planned)
- Collaboration with HR, facilities, finance, development, and other business units
This unified view helps agents access context across related projects, assets, and owners.
Example: Automated incident handling
A service director creates an Incident board and links it to an Initiatives board. An AI Block categorizes incoming tickets. A Power-up routes each one to the right team. The Service Tracker flags patterns and volume spikes for leaders.
Easy to use and customize — rapid adoption and no-code flexibility
Teams adopt up monday service quickly due to its familiar interface and straightforward configuration model.
What drives adoption:
- Best-practice templates for core ITSM workflows
- A clean, intuitive interface
- No-code customization so teams update processes without developers
- Open API and integrations for CRM, identity, and asset systems
- Lower long-term overhead because administrators manage changes without specialized configuration work
These capabilities support fast rollout and ongoing improvements.
AI and automations — transform service delivery at scale
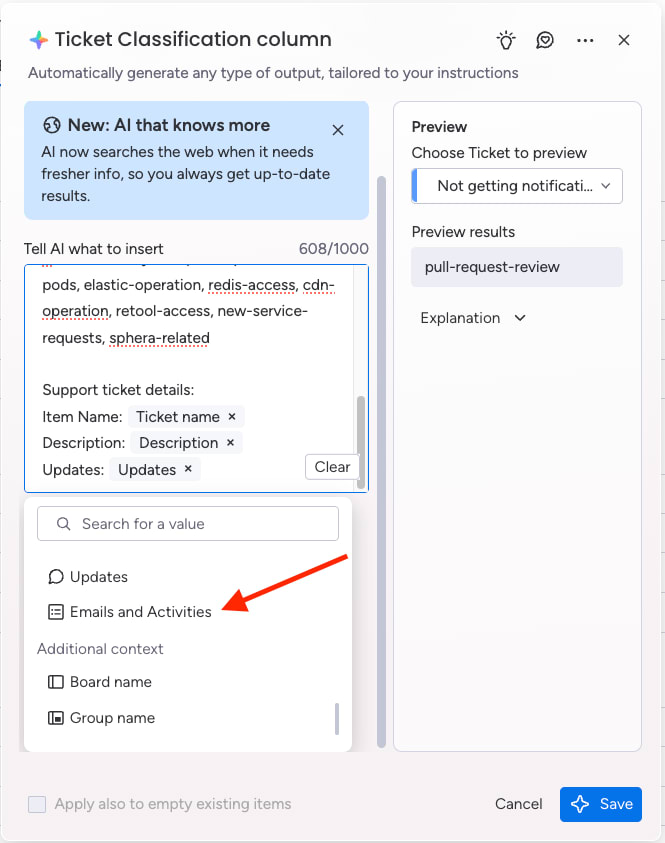
Automation reduces repetitive work. AI sharpens accuracy and speeds up response during busy periods.
Examples include:
- AI Blocks for ticket classification, routing, and summarization
- Automated responses, escalations, approvals, and SLA tracking
- Digital Workers that monitor patterns, generate reports, and surface recurring issues
- Instant summaries for long threads so agents get context quickly
These features help teams maintain high-quality service and shorten resolution times.
How monday service’s AI pieces work together in one workflow
A request arrives through Outlook. An AI Block identifies its category. A Power-up sends it to the right queue. A Digital Worker tracks progress, sends updates, and generates weekly summaries for leadership. Each component contributes to a smoother workflow.
Real-time analytics — steer your ITSM roadmap with data
Analytics within monday service combine ticket metrics, project timelines, and resource data in one view.
Useful insights include:
- SLA performance
- Ticket volume by category, requester, or business unit
- MTTR, resolution time, and first-contact resolution
- Change success rates and failure patterns
- CSAT and sentiment trends
These dashboards help leaders identify issues early, plan staffing, and guide roadmap decisions.
From IT to enterprise service management on monday service
Many departments run workflows that mirror IT service delivery. monday service gives them a shared structure to manage requests, approvals, and documentation.
Where teams apply this model:
- HR (onboarding, access requests, workforce support)
- Facilities (maintenance, repairs, reservations)
- Finance (procurement, invoice support, vendor requests)
- Legal, security, and operations teams
A unified workspace helps every group work from the same information and coordinate handoffs with clarity.
Example: Hybrid cloud governance
Teams track cloud assets, on-prem servers, and SaaS tools in a CMDB-style board. Changes link directly to these items, creating an audit trail.
ITSM best practices checklist and next steps
This checklist gives leaders a quick way to validate their current approach and identify areas for improvement.
ITSM best practices checklist
A high-level list your team can use immediately:
- Align services, SLAs, and KPIs with business priorities so success is clearly defined
- Standardize core workflows for incidents, requests, problems, and changes
- Introduce automation for classification, routing, and SLA tracking
- Strengthen change and knowledge practices to support consistency
- Track metrics that show operational and business impact
- Extend service workflows to HR, facilities, finance, and other groups
- Maintain accurate configuration data and governance for hybrid cloud environments
- Use analytics to assess performance trends and guide ongoing improvements
These practices create scalable operations and help teams deliver consistent, reliable service.
Where to start on your ITSM best practices journey
The most effective ITSM improvements usually begin with a narrow, well-defined focus. Many teams start with one foundational process — often incident management — to establish clarity and build early confidence. Introducing a single automation that removes repetitive steps can create immediate relief for agents and demonstrate the value of a more streamlined workflow. Another common first move is refreshing the knowledge base, which strengthens self-service and reduces friction for users and support teams.
Small, meaningful changes like these give organizations momentum without overwhelming day-to-day operations. They also set the stage for broader improvements as teams get comfortable with new practices and see the impact firsthand.
Explore how monday service can help your team put these practices into action with less setup time and a smoother path to adoption.
FAQs
What is the primary difference between ITIL and ITSM?
ITIL provides a structured set of guidelines for managing IT services. ITSM focuses on the operational work involved in delivering, supporting, and improving those services. Many teams use ITIL as a reference when shaping their ITSM processes.
How does ITSM knowledge management directly reduce service desk costs?
Effective knowledge management lowers incoming ticket volume, shortens handle time, and helps new agents learn faster. Reusable articles also reduce rework during escalations and handoffs.
What is change management’s role in a high-velocity IT environment?
Change management helps organizations move quickly while controlling risk. Teams rely on risk-based approvals, documented workflows, and post-implementation reviews to support safe, predictable deployments in fast-moving environments.
Can ITSM best practices be applied to non-IT departments?
Yes. HR, facilities, finance, legal, and operations teams all manage structured requests and recurring service cycles. ITSM principles help them bring clarity to intake, approvals, communication, and documentation.
What are the key considerations for implementing ITSM in a hybrid cloud setup?
Hybrid cloud requires accurate configuration data, clear governance, dependable integrations, and visibility into dependencies that span multiple hosting models.
What is a Known Error Database (KEDB), and why is it essential for problem management?
A KEDB stores documented issues, confirmed root causes, and validated workarounds. It reduces time spent rediscovering solutions and helps teams prevent repeat incidents.
Which ITSM practice has the biggest influence on user satisfaction?
Clear SLAs, well-written knowledge articles, and timely communication during incidents tend to have the greatest impact on user satisfaction scores.
What should teams consider when implementing a new ITSM system?
Most teams begin with a process mapping exercise, choose best-practice templates, run a pilot, evaluate user adoption, and revise workflows based on real usage patterns.
How will AI change the role of the traditional IT service agent by 2026?
AI will absorb many routine tasks — classification, summarization, routing, and status updates — allowing agents to focus on complex investigations, improvement initiatives, and work that requires coordination across multiple teams.