Service teams rely on monitoring tools to uphold their service level agreements, but these tools often act more like scorekeepers than coaches. They tell you when you’ve already failed instead of helping you prevent the breach. The alerts arrive too late, after the damage occurs and you risk losing customer trust. AI models shift this approach from reactive alerts to proactive prevention. Instead of just tracking metrics against fixed thresholds, AI analyzes complex patterns across systems to forecast disruptions before they impact customers, connecting signals that humans often miss and turning data into clear warnings of what’s likely to happen next.
This article walks through the essential AI capabilities that protect your SLAs, from automated routing to predictive maintenance. We will explore the data foundation required for accurate predictions and the specific risks AI can prevent automatically. By the end, you will have a clear, five-step plan for deploying AI to move your team from firefighting to focused, intelligent service management with platforms like monday service.
Key takeaways
- Traditional monitoring fails: Alert fatigue and late detection prevent violation prevention, while manual tracking can’t handle complex environments.
- No-code AI transforms SLA management: Automatic ticket routing, risk prediction, and real-time analytics require no engineering resources with platforms like monday service.
- Six risks prevented automatically: Response delays, resolution bottlenecks, system downtime, capacity overload, compliance gaps, and customer satisfaction drops.
- Fast results and ROI: Most teams see useful AI predictions within 2 to 6 weeks and measurable ROI within one quarter.
Why SLA breaches happen despite monitoring tools
Service level agreements (SLAs) define the commitments you make to customers around response time, resolution time, uptime, and compliance targets. SLA breaches happen when you fail to meet these standards.
Traditional monitoring tools track system health and trigger alerts, but they fail to prevent breaches because they only surface symptoms without predicting impact.
Alert fatigue overwhelms teams with excessive low-value notifications. This constant noise trains people to ignore or delay responses, burying critical signals.
Manual tracking can’t keep pace with modern service environments. Humans can’t correlate data across multiple systems fast enough, and spreadsheets only show what’s already broken.
Reactive systems detect problems too late. By the time a “latency > 2 seconds” alarm triggers, queues have formed and the breach is inevitable.
How AI predicts service disruptions before they impact SLAs
AI shifts service management from reactive response to predictive prevention by evaluating combinations of signals, timing, and context to estimate which issues will violate SLAs and when.
Machine learning algorithms learn patterns from historical data rather than following fixed rules. They recognize that server CPU usage above 85% combined with increased login attempts typically leads to response-time violations within 30 minutes.
Predictive analytics forecasts future outcomes with specific probabilities, like “72% chance of breaching the P1 60-minute response SLA,” based on ticket backlog, staff availability, and past incidents. Understanding the differences between SLA vs SLO vs SLI helps teams set the right targets for AI models to monitor and protect.
Anomaly detection identifies unusual patterns that deviate from normal behavior. A sudden spike in authentication retries or an unusual sequence of microservice calls can signal an impending incident. monday service leverages these AI capabilities to automatically classify and route high-risk tickets before they breach.
Essential AI capabilities for proactive SLA protection
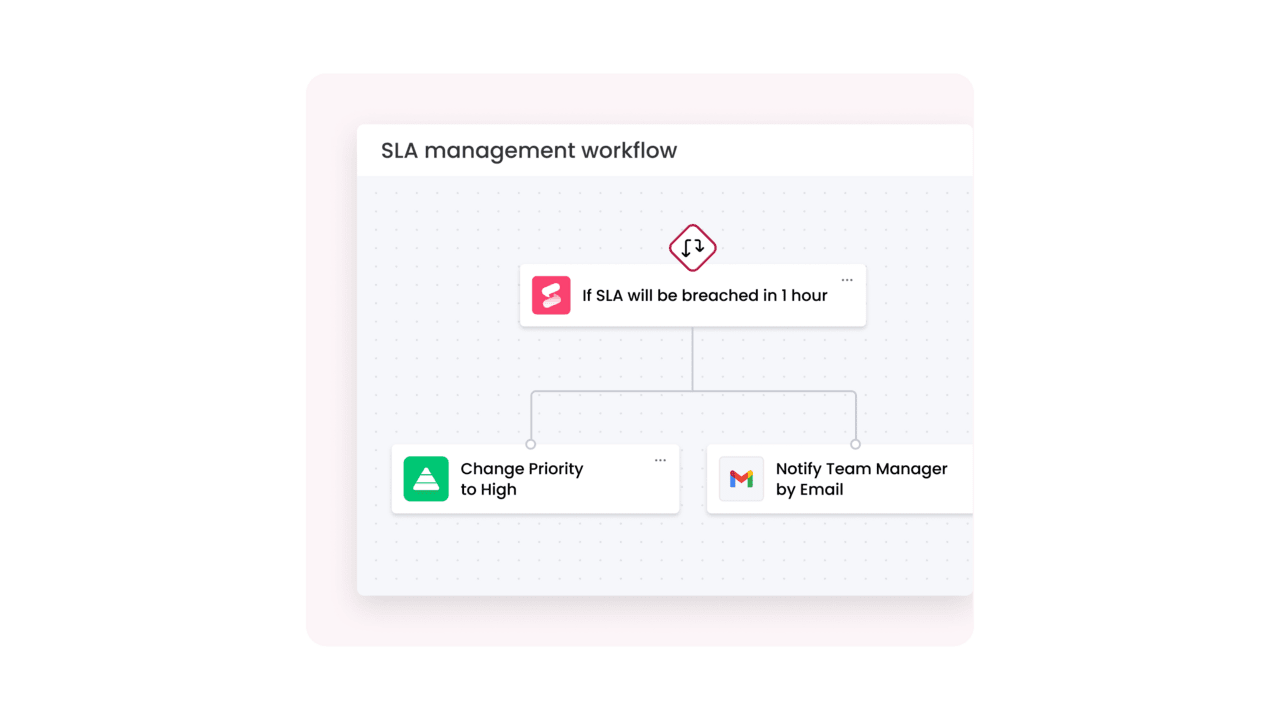
The capabilities that prevent breaches share a theme: they reduce time-to-correct-action while improving accuracy about what matters. Four capabilities consistently translate into fewer violations and less operational chaos:
- Automated incident classification and smart routing: AI categorizes incidents by type, severity, and likely affected services, then routes them to the right resolver group immediately. This reduces triage delays that often consume the first 10 to 20 minutes of an SLA window. Platforms like monday service automate this routing without requiring custom code or engineering resources.
- Natural language processing for faster resolution: NLP enables AI to interpret human language in tickets, emails, and chat transcripts. It extracts entities like service names and error codes, summarizes the problem, and links similar past incidents. This capability turns unstructured text into actionable insights that speed up resolution.
- Real-time workload optimization: AI monitors demand, queue depth, and staff capacity, then adjusts workload distribution to keep SLAs intact. It shifts assignments to available agents with the right skills and balances queues. Tools like monday service provide this optimization through visual workflows that teams can configure and adjust as needs change.
- Self-learning performance thresholds: These adjust alert sensitivity based on seasonality, deployments, and usage shifts. Self-learning thresholds reduce false positives by recognizing “normal busy” patterns while still flagging true risk.
Data foundation for AI-powered risk prevention
AI performance depends on data quality and integration. Incomplete or inaccurate data produces confident-but-wrong predictions, while strong foundations combine the right sources, quality standards, and security guardrails.
Critical data sources include service metrics, user behavior patterns, system logs, and incident history. Integration challenges include mismatched identifiers, inconsistent timestamps, and data siloed across teams.
Data quality means completeness, accuracy, and timeliness. Missing ticket fields like “affected service” cause misrouting and weak predictions, while delayed metrics turn forecasts into hindsight.
Security and compliance shape how service data is stored and accessed. Common frameworks include ISO 27001, SOC 2, GDPR, and HIPAA. Effective programs balance model usefulness with protection through role-based access, encryption, and data minimization.
6 SLA risks AI models prevent automatically
AI reduces the most common, measurable causes of SLA violations by acting earlier and routing work more intelligently. These risks map directly to the SLAs leaders already track.
1. Response time violations through intelligent prioritization
AI prioritizes incidents based on SLA impact and business criticality rather than arrival order. When a ticket affects a revenue checkout flow, it jumps ahead of multiple low-impact requests. Intelligent routing then places the incident with the right expert immediately.
2. Resolution delays with automated escalation
AI monitors progress signals and escalates before deadlines approach. When an incident sits untouched for 20 minutes during a P1 window, the system triggers a supervisor notification or reassignment.
3. System downtime using predictive maintenance
AI predicts component failures and schedules maintenance during planned windows. Storage devices showing rising read error rates get flagged before they fail catastrophically, preventing unexpected outages.
4. Capacity overload via dynamic resource allocation
AI detects demand spikes early and scales resources to maintain performance. When it detects accelerating load, the system allocates additional compute or rebalances workloads across regions.
5. Compliance gaps through continuous monitoring
AI continuously checks service delivery against requirements like access controls and audit logging. The system flags missing approvals or policy drift that could violate contractual SLAs.
6. Customer satisfaction drops with sentiment analysis
Sentiment analysis evaluates customer messages for dissatisfaction signals. Early detection highlights accounts at risk before they escalate into formal complaints, giving teams time to intervene.
Real-time alerts vs predictive AI prevention
Traditional real-time alerts and predictive AI prevention serve different purposes in SLA management. Understanding when to use each approach helps you build a more resilient service operation.
Real-time alerts trigger after a metric crosses a threshold. They minimize time-to-detect but don’t reliably prevent breaches. High noise and static thresholds lead to alert fatigue, training teams to ignore warnings until it’s too late.
Predictive AI prevention triggers before impact based on risk accumulation and patterns. It produces lower noise as models learn which signals correlate with breaches. The system adapts to normal patterns and adjusts sensitivity over time, reducing false alarms while catching real risks earlier.
| Feature | Real-Time Alerts | Predictive AI Prevention |
|---|---|---|
| Trigger timing | After threshold breach | Before impact occurs |
| Detection basis | Static thresholds | Pattern recognition and risk accumulation |
| Noise level | High (alert fatigue common) | Low (learns relevant signals) |
| Adaptability | Manual threshold adjustments | Self-adjusting based on patterns |
| Best use case | Immediate critical issues | Preventing future breaches |
The most effective approach combines both methods. Teams using monday service get real-time alerts to handle immediate issues while predictive AI flags risks before they escalate. This dual approach keeps teams responsive without overwhelming them with noise.
Try monday service5 steps to deploy AI for SLA risk management
Deploying AI for SLA protection follows a structured path from assessment to continuous improvement. These five steps help you move from reactive monitoring to proactive prevention without overwhelming your team or requiring extensive technical resources.
Step 1: Analyze current SLA performance metrics
Start by examining breach frequency, severity, and drivers by service and team. Look at response time distribution, resolution patterns, and breach root causes to identify patterns like “P2 breaches cluster on weekends” that represent the best targets for AI prevention. Dedicated SLA software helps you track these metrics consistently and identify improvement opportunities.
Step 2: Set AI prevention goals and KPIs
Goals should tie directly to SLA outcomes. Target specific improvements like “reduce P1 response-time breaches by 30% in 60 days” and track breach rates, downtime avoided, and automation success rates.
Step 3: Connect AI models to service platforms
Integration connects ticketing and monitoring systems through APIs, webhooks, or native integrations. With 72+ integrations that connect without custom code, monday service simplifies this process significantly.
Step 4: Configure automated workflows and responses
Match automation strength to confidence and impact. Low-risk actions include ticket enrichment and routing, while higher-risk actions like infrastructure scaling require approval gates.
Step 5: Launch continuous learning and optimization
Feed outcomes back into the system to improve accuracy. Track which predictions were correct and which automations helped, while monitoring for changes in traffic patterns that might reduce model performance.
Measuring AI impact on service performance
Implementing AI for SLA management is only valuable if you can measure its impact and demonstrate clear results. Track the right metrics to prove AI value and guide continuous improvement. Focus on three categories:
- ROI metrics: Avoided SLA penalties, reduced downtime costs, and labor saved on manual triage show financial impact.
- Efficiency gains: Reduced escalations, improved first-contact resolution, lower backlog age, and faster acknowledgment and resolution times demonstrate operational improvement.
- Success indicators: Prediction accuracy and false positive rates reveal model health. Healthy systems show improving precision with stable coverage of true risks.
Built-in analytics from platforms like monday service let you track these metrics in real time without switching between systems.
Evolution from basic automation to autonomous AI agents
Basic automation handles repetitive steps like ticket routing, while advanced systems reason about tradeoffs and take goal-directed action. Agentic AI can diagnose issues, run remediation, and verify recovery independently.
A 90-day implementation typically starts with foundation and visibility, then progresses through prediction and scaling. This structured approach helps teams move from reactive monitoring to proactive prevention without overwhelming resources.
| Phase | Timeline | Key Activities |
|---|---|---|
| Foundation and visibility | Month 1 | Integrate systems, establish baselines, connect data sources |
| Prediction and guided action | Month 2 | Deploy predictive models, configure smart routing, set up alerts |
| Scale prevention and refine | Month 3 | Expand automation, optimize workflows, measure outcomes |
Building AI-first operations means designing workflows around fast, consistent decisions. Teams adopt AI faster when automation is transparent and measured against shared SLA goals.
How monday service transforms SLA management with AI
Service teams need AI-powered prevention without the complexity of custom engineering. With monday service, you get intelligent SLA protection through a visual, no-code platform that your team can configure and adapt as service demands evolve.
The platform brings together AI capabilities, cross-functional visibility, and automated workflows in one unified system. Your service operation shifts from reactive firefighting to proactive prevention, protecting SLAs before breaches occur.
AI-powered ticket routing and classification

Intelligent automation categorizes incoming tickets by type, urgency, and affected services, then routes them to the right resolver instantly. This eliminates manual triage delays that consume critical SLA time. The AI learns from resolution patterns to improve routing accuracy continuously, ensuring high-priority incidents reach skilled agents within seconds of arrival.
Predictive analytics and risk detection
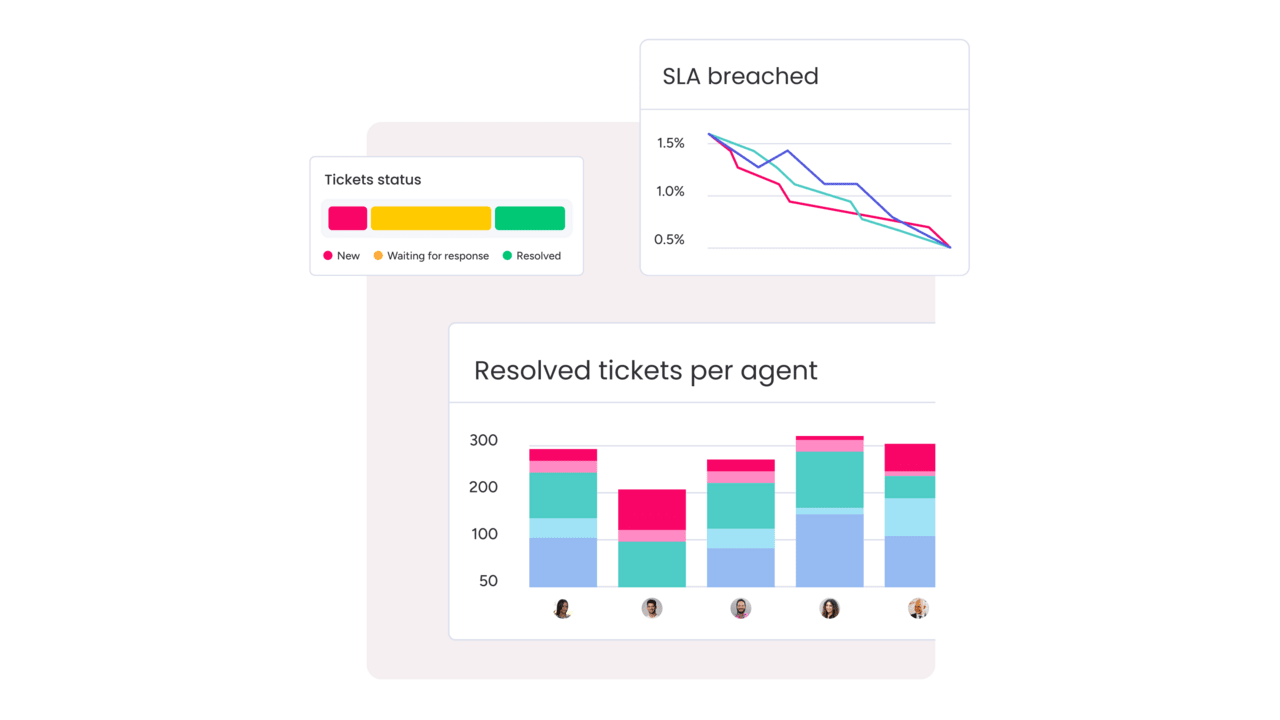
Built-in AI models analyze ticket volume, response patterns, and system signals to forecast SLA risks before they materialize. Service leaders see probability-based warnings directly in their dashboards, with clear context about which SLAs face the highest breach risk. The system identifies unusual patterns and capacity constraints early, giving teams time to intervene before customers are impacted.
No-code workflow automation
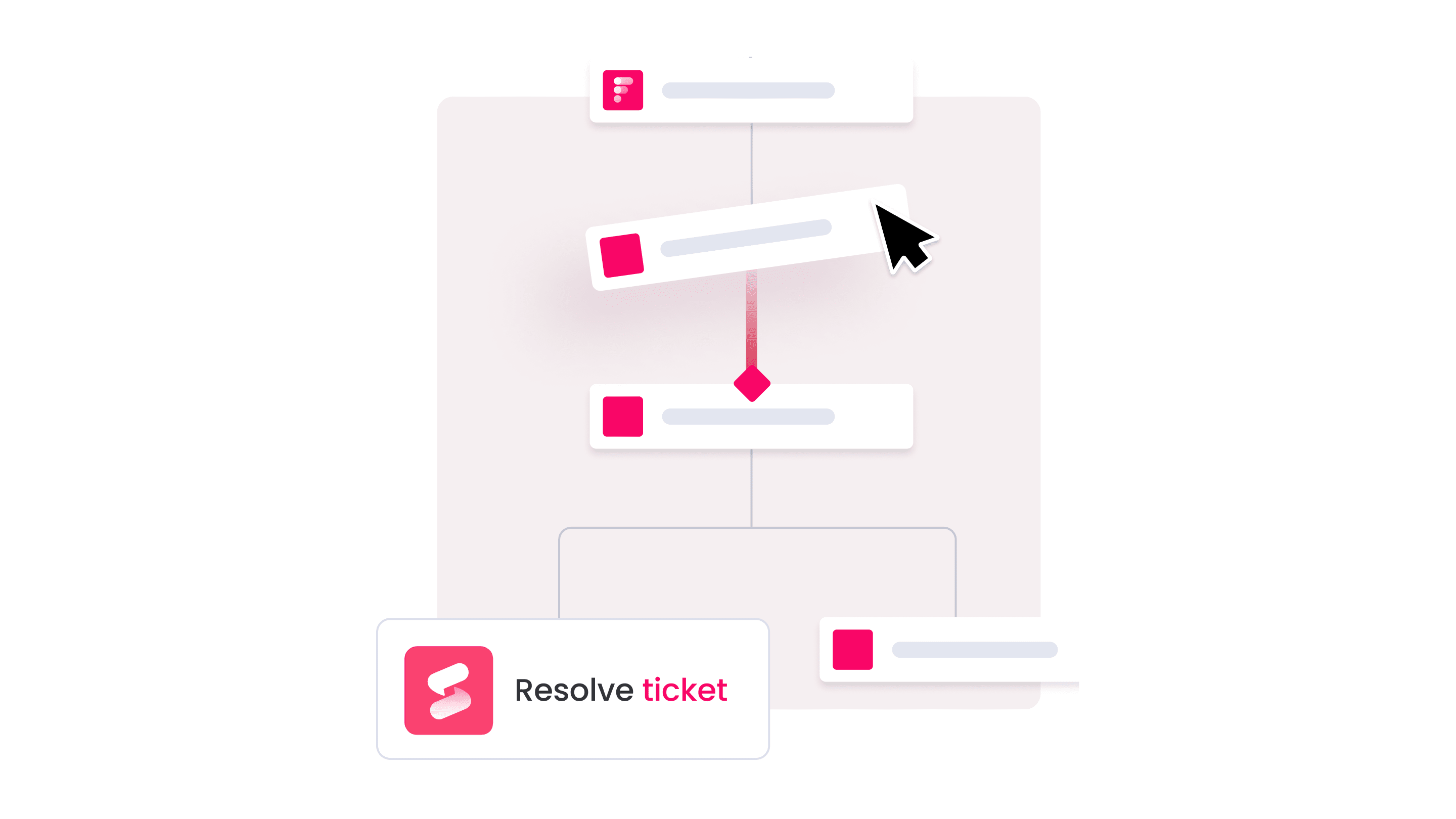
Visual workflow builders in monday service let you configure escalations, notifications, and automated responses without writing code or depending on engineering resources. You can set up intelligent rules that trigger based on SLA countdown timers, ticket age, or AI-detected risk levels. Teams adjust automation logic as service requirements change, maintaining control without technical bottlenecks.
Unified cross-department visibility

IT, HR, customer support, and operations teams work from the same intake and prioritization system, eliminating silos that hide dependencies and slow resolution. Shared dashboards surface workload distribution, SLA status, and AI-flagged risks across all service functions. This transparency reduces duplicate work and clarifies ownership when incidents span multiple teams. Organizations implementing enterprise service management benefit from this unified approach across departments and geographies.
"Our team LOVES the monday service platform and we’re already exploring how we could incorporate it for other departments, too. It has streamlined our workflow in a way that both our team and customers appreciate."
Andrew Marshall | VP Operations
״monday service provides clear insights into requests volume and types, response times, and trends - helping us continuously improve operations"
Grant De Waal-Dubla | CIO
"The biggest value for us is speed and flexibility. You can get up and running in days, change anything instantly, and see everything in real time. And you don’t need a dedicated admin to do it."
Clive Camilleri | Head of People Tech & OperationsStart preventing SLA breaches with intelligent service management
AI-powered prevention replaces firefighting with proactive interventions that protect service quality before customers notice issues. Machine learning identifies risks early, while smart routing shrinks response times across your operation. Strong data foundations keep predictions accurate, and measurable outcomes prove clear value to leadership. The result is SLA improvements that stick and compound over time.
Teams ready to move from reactive monitoring to intelligent prevention can start immediately with platforms like monday service, which combines AI-powered risk detection, automated routing, and visual workflows in one unified system.
Try monday serviceFAQs
How long does it take for AI models to start preventing SLA breaches?
AI models typically produce useful early signals within 2 to 6 weeks once integrations and baseline data are in place. Stronger prevention outcomes emerge over 2 to 3 months as the system learns your specific patterns. Most teams notice measurable improvements in breach rates and response times by the end of the second month.
What's the minimum data required for accurate SLA predictions?
Accurate predictions require several months of incident history plus current telemetry like latency, errors, and saturation. The data needs consistent timestamps and labels to train models effectively. Teams with at least three months of clean historical data typically see the most reliable predictions from the start.
Can AI adapt to changing service level requirements?
Yes, AI adapts when models retrain on recent behavior. The system learns new SLA targets and service patterns through continuous monitoring and adjustment. This means your AI protection stays effective even as you introduce new services or modify existing commitments.
How does AI reduce false positive alerts in service management?
AI reduces false positives by learning which signal combinations reliably precede incidents. It adjusts sensitivity based on normal seasonality rather than using static thresholds. Over time, the system becomes better at distinguishing between routine fluctuations and genuine risks that require action.
Which service management platforms integrate best with AI models?
Platforms with strong APIs, webhook support, and native monitoring integrations work best. With built-in AI capabilities that reduce integration overhead, monday service is designed for seamless AI integration. This approach eliminates the need for custom development and lets teams activate AI features without engineering resources.
What's the typical ROI timeline for AI-powered SLA management?
Operational gains appear within one quarter through reduced triage time. Larger ROI from avoided downtime and breach penalties typically shows within 6 to 12 months. Teams that track metrics consistently often see compounding returns as AI models improve and automation coverage expands.