Your database just crashed because someone entered the same customer ID for two different people. Or your inventory system shows conflicting product prices across departments, and no one knows which number is correct. These common breakdowns stem from one issue: databases that don’t enforce clear rules about how data relates.
Functional dependencies in DBMS define which pieces of information determine other pieces. When you establish that a customer ID maps to one customer name, or that a product code determines a price, you’re defining a functional dependency. These relationships form the backbone of database design and keep information consistent as data grows.
This guide walks through 7 types of functional dependencies, shows how to identify them in real business scenarios, and explains how they guide normalization decisions that prevent costly data problems. You’ll also see how teams document and maintain these data relationships using structured workflows in monday work management.
Get StartedKey takeaways
- Clear dependency rules stop duplicate records, conflicting updates, and structural inconsistencies before they spread.
- Understanding full, partial, and transitive dependencies helps you normalize tables and reduce redundancy as data grows.
- Statements like “each customer has one ID” translate directly into functional dependencies that shape table design.
- Shared documentation and clear ownership keep dependency rules accurate as systems evolve.
- Teams can use monday work management to log dependency rules, assign owners, and monitor data quality issues in a structured workflow.
What are functional dependencies in DBMS?
Functional dependencies define how one attribute determines another within a database. They establish clear rules that keep related data consistent across tables.
A functional dependency exists when one attribute, called the determinant, uniquely determines another attribute, called the dependent. For example, if CustomerID always maps to one CustomerName, then CustomerID → CustomerName is a functional dependency.
When these relationships are defined correctly, databases stay structured as they grow. Without them, duplicate records, inconsistent updates, and structural errors become more likely.
Why functional dependencies matter for data quality
Functional dependencies prevent three common types of data anomalies:
- Update anomalies: The same data stored in multiple places leads to inconsistent changes.
- Insertion anomalies: Poor table structure blocks valid new records.
- Deletion anomalies: Removing one record unintentionally removes related information.
These issues affect reporting accuracy, operational workflows, and compliance processes. Clear dependency design reduces the risk of data conflicts and structural instability.
Writing functional dependencies
Documenting functional dependencies requires precision. Put determinants on the left and dependents on the right.
Step 1: Identify the determinant: Choose the attribute that uniquely identifies something. For example, SocialSecurityNumber determines identity.
Step 2: Validate consistency: If ZipCode determines City, then each ZIP Code must always map to the same city.
Step 3: Address composite determinants: Some relationships require multiple attributes. In a grading system, {StudentID, CourseID} → Grade captures the full relationship.
Step 4: Document assumptions: If exceptions exist, the dependency may not be valid. A rule with frequent edge cases should not be treated as absolute.
7 types of functional dependencies

Understanding dependency types helps you evaluate schema structure and determine how a table behaves under normalization. Each type highlights a specific relationship pattern that affects redundancy and data consistency.
Trivial functional dependencies
A dependency is trivial when the dependent is already part of the determinant. For example, {EmployeeID, EmployeeName} → EmployeeName is always true, but it does not influence schema design.
Trivial dependencies can be acknowledged and set aside during normalization.
Non-trivial functional dependencies
A non-trivial dependency exists when the dependent is not part of the determinant. For example, SSN → BirthDate defines a real structural rule. These dependencies shape how tables are organized and where attributes belong.
Partial functional dependencies
Partial dependencies appear when a non-key attribute depends on only part of a composite key.
In a table with primary key {OrderID, ProductID}, if ProductID → ProductName, then ProductName depends only on ProductID. This structure causes duplication across rows.
Resolving partial dependencies typically involves separating attributes into their own tables so each fact is stored once.
Full functional dependencies
A full dependency requires the entire composite key to determine a non-key attribute.
For example, {OrderID, ProductID} → QuantityOrdered requires both identifiers. The quantity depends on the combination, not either attribute alone.
Tables structured around full dependencies reduce repetition and support cleaner normalization.
Transitive functional dependencies
A transitive dependency occurs when one attribute determines another through an intermediate attribute.
If EmployeeID → DepartmentID and DepartmentID → DepartmentLocation, then DepartmentLocation should be stored in a department-level table rather than repeated with each employee record.
Separating indirect relationships helps maintain consistency as records change.
Multivalued dependencies
Multivalued dependencies occur when one attribute relates to multiple independent values.
If EmployeeID →→ Degree and EmployeeID →→ Project, combining these in one table creates unnecessary repetition. Separating independent facts keeps tables structured and easier to maintain.
Approximate functional dependencies
Some relationships hold true for most records but include exceptions. Approximate dependencies describe these patterns.
For example, ZipCode → State may apply in nearly all cases, with limited edge scenarios that require review. Identifying these relationships helps teams flag inconsistencies without enforcing rigid constraints that block operations.
Real-world dependency examples
Here’s how these concepts work in real business scenarios. These examples show how dependencies shape your tables and stop redundancy.
Employee database dependencies
Employee databases contain personal details, roles, and department assignments. These dependencies show you how to structure data without repeating yourself:
The transitive dependency indicates that DeptName should be moved to a separate Department table linked by DeptID. This stops redundancy when multiple employees work in the same department.
E-commerce system dependencies
E-commerce platforms juggle relationships between customers, orders, and inventory. Dependencies keep shipping addresses consistent and preserve pricing history:
- Customer consistency: CustomerID → {CustomerName, CurrentAddress} maintains a single source of truth for customer profiles
- Order integrity: OrderID → {OrderDate, CustomerID} creates a fixed snapshot at order time
- Line item specifics: {OrderID, ProductID} → {Quantity, UnitPrice} preserves historical pricing even when catalog prices change
University database patterns
Academic systems track students, courses, and instructors through these dependencies:
- Student data: StudentID → {Name, Major}
- Course data: CourseID → {Title, Credits}
- Enrollment: {StudentID, CourseID} → Grade exists only at the intersection
- Section assignment: ClassSectionID → InstructorID ensures one instructor per section
How functional dependencies drive database design
Functional dependencies shape how tables are structured, how keys are selected, and how relationships are defined. When these relationships are clearly identified, database models remain organized as systems grow.
The determinant-dependent relationship
The determinant-dependent relationship clarifies direction. If one attribute determines another, that relationship should be reflected directly in the table design. When it is not, inconsistencies and unnecessary duplication follow.
Dependencies and database keys
Dependencies show you which attributes should be database keys. A superkey is any set of attributes that determines all the other attributes. A candidate key is a minimal superkey. No subset of it can determine all attributes. The primary key is whichever candidate key you pick to identify rows.
If attribute A determines all other attributes (A → All), then A can be your primary key. If your proposed key can’t determine certain attributes, it won’t work as a primary key.
Functional dependencies in normalization
Normalization organizes data to reduce redundancy and clarify ownership of information. Functional dependencies guide how tables are structured at each stage.
First Normal Form and atomic values
First Normal Form (1NF) requires that each column store a single value. Dependencies apply to atomic values, not lists.
If a column stores multiple phone numbers in one field, functional dependencies cannot be enforced accurately. Structuring data at the atomic level enables clear relationships.
Second Normal Form
Second Normal Form (2NF) applies to tables with composite keys. It requires that every non-key attribute depend on the entire key.
When an attribute relates to only part of a composite key, it signals that the table is combining facts that belong in different structures. Separating those attributes aligns each table with its true determinant and reduces repeated data across records.
Third Normal Form
Third Normal Form (3NF) addresses indirect relationships.
If a non-key attribute depends on another non-key attribute rather than directly on the primary key, that relationship should be modeled independently. Isolating indirect dependencies clarifies ownership of information and prevents update conflicts when related values change.
Boyce-Codd Normal Form requirements
Boyce-Codd Normal Form (BCNF) strengthens 3NF by requiring that every determinant in a non-trivial dependency be a candidate key.
BCNF refines table structure in cases where overlapping keys create ambiguity. Teams weigh this level of normalization against reporting complexity and performance considerations.
4 steps to identify functional dependencies
Identifying functional dependencies requires technical review and business input. These methods help document relationships accurately.
Step 1: Analyze business rules
Business rules become functional dependencies. When policy states “each department has exactly one manager,” this becomes DepartmentID → ManagerID. Talk to stakeholders to understand operational constraints, then turn them into dependency notation.
Step 2: Examine data patterns
Your legacy data shows patterns that point to dependencies. Run queries on distinct value counts to see if your candidate determinants always pair with unique dependents. Watch out: patterns in small datasets might be coincidence, not actual rules.
Step 3: Use automated discovery
Profiling software scans your datasets and detects functional dependencies automatically. These tools calculate correlations between columns to find possible determinants. Automated discoveries work well for large datasets, but you still need humans to verify they make business sense.
Step 4: Validate with domain experts
Data patterns show what’s there. Experts tell you what should be there. Your dataset might show every ProductCode has a unique Price, which looks like a dependency. But domain experts might tell you prices vary by region, so the real dependency is {ProductCode, RegionID} → Price.
AI-powered dependency discovery
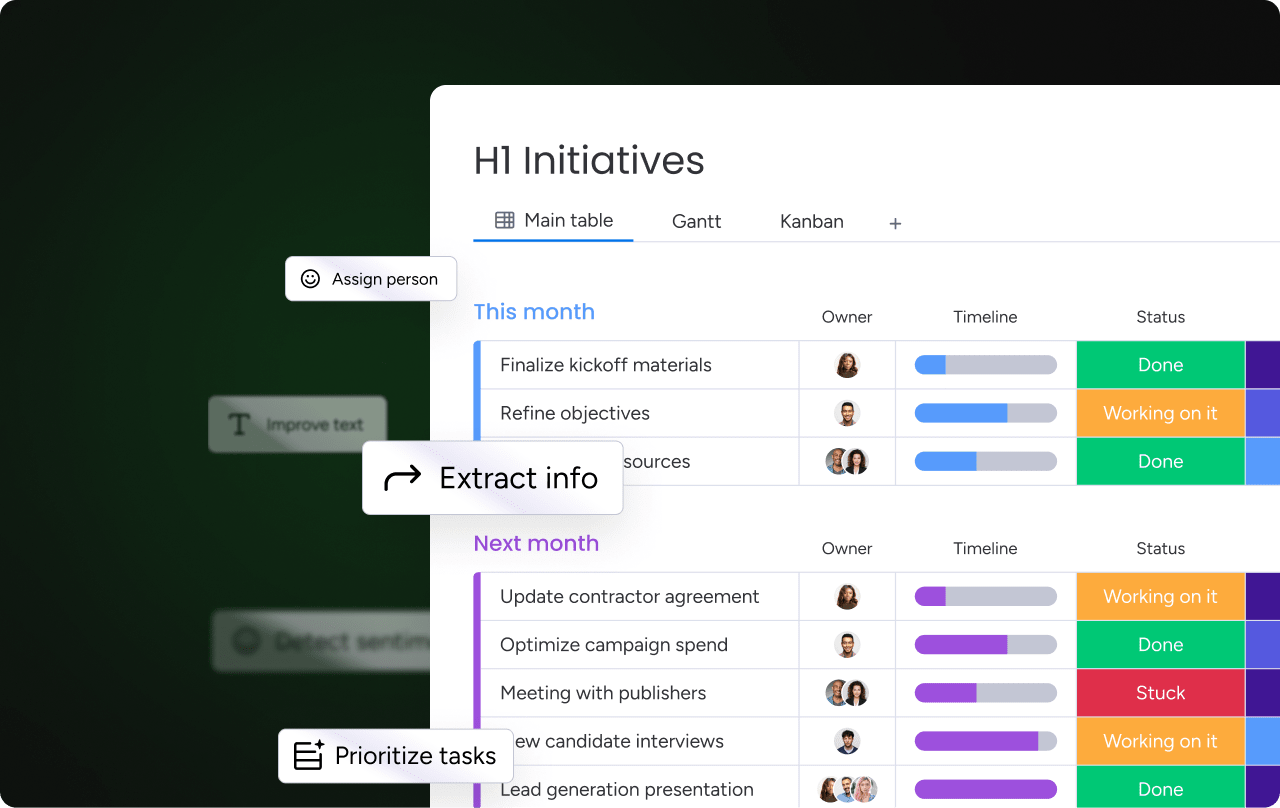
Large datasets can make dependency review time-consuming. Automated profiling tools analyze column patterns and suggest likely determinant relationships.
These systems surface high-confidence patterns, but domain validation remains essential. Suggested dependencies should reflect real business rules before being adopted into schema design.
Human-in-the-loop validation
Automated suggestions accelerate discovery, but human review confirms accuracy.
Database administrators and domain experts assess proposed relationships, validate assumptions, and determine whether exceptions represent errors or legitimate edge cases.
Managing relaxed dependencies
Some relationships are statistically strong without being absolute. Instead of blocking processes for minor violations, teams monitor exceptions and evaluate them case by case.
This approach maintains operational continuity while improving data quality over time.
Best practices for dependency management
Dependency management extends beyond initial schema design. As business requirements change, tables and relationships evolve. Clear governance keeps dependency rules aligned with operational needs.
Version control for dependency rules
Business logic changes over time. A rule such as Product → Price may no longer apply when pricing varies by region. Tracking dependency definitions through version control creates visibility into updates and preserves historical context.
Continuous monitoring and alerts
Dependencies need active monitoring. Automated checks validate key relationships and surface violations when records conflict. Early detection reduces downstream data corrections and reporting errors.
Cross-team collaboration
Data governance requires collaboration across technical and business teams. Developers, DBAs, and business analysts must work together to define and maintain dependencies. Establish shared glossaries and decision logs so everyone understands why dependencies exist. Regular governance meetings help business stakeholders communicate new requirements that might necessitate dependency updates.
Get StartedTransform dependency management with monday work management
Database governance requires coordination across engineering, analytics, and business stakeholders. monday work management provides a structured workspace where dependency rules are documented, reviewed, and tracked in one place.
Visual dependency documentation
Boards centralize functional dependency records with clear ownership, status tracking, and revision history. Views such as dashboards and timelines provide visibility into review cycles and open issues across teams.
Automated validation workflows

Automations can create items when validation tools flag inconsistencies. Routing rules assign issues to the appropriate data steward based on domain, reducing response time and manual coordination.
Real-time visibility
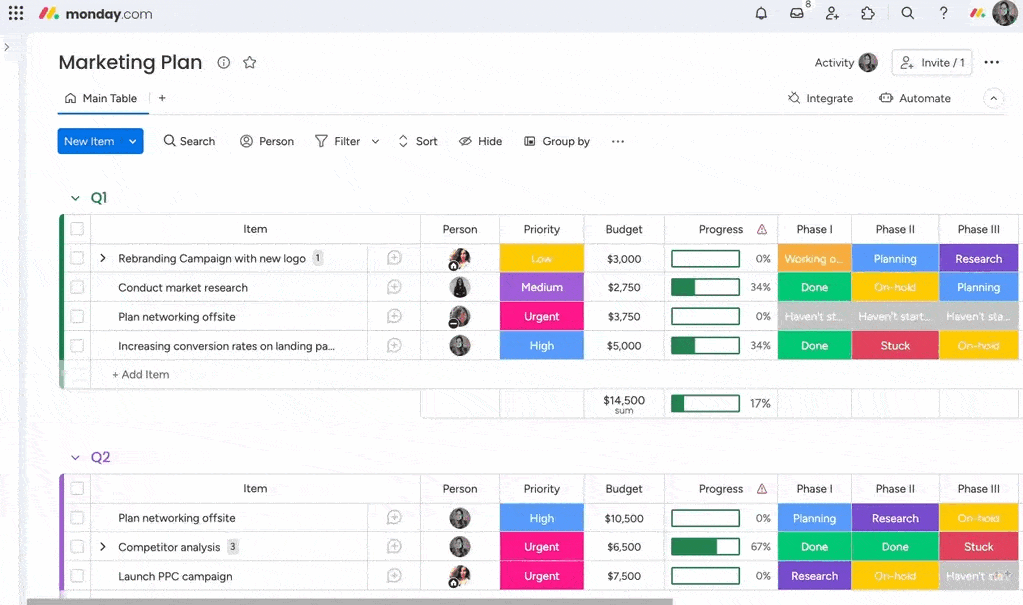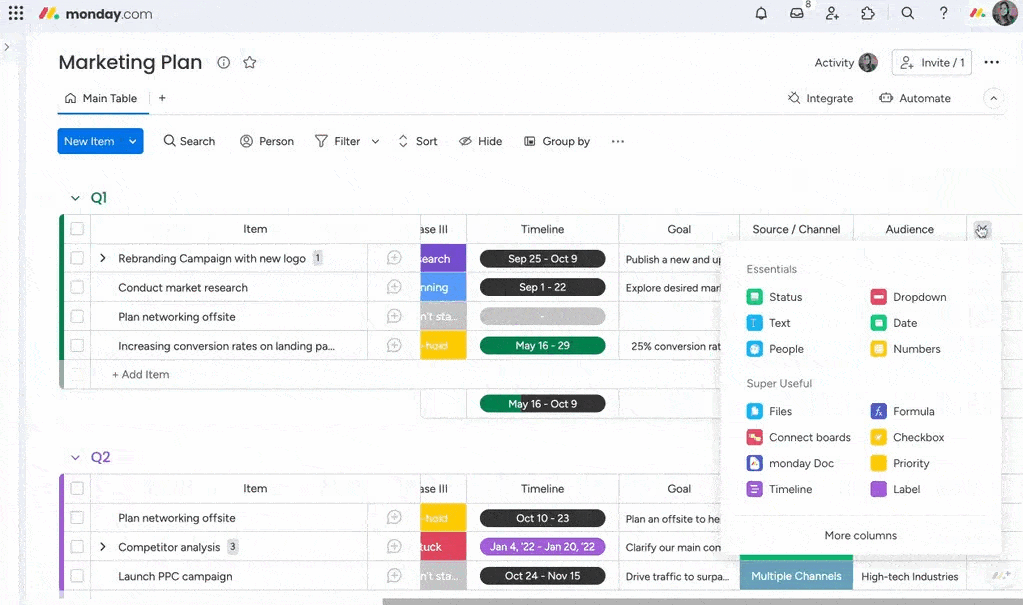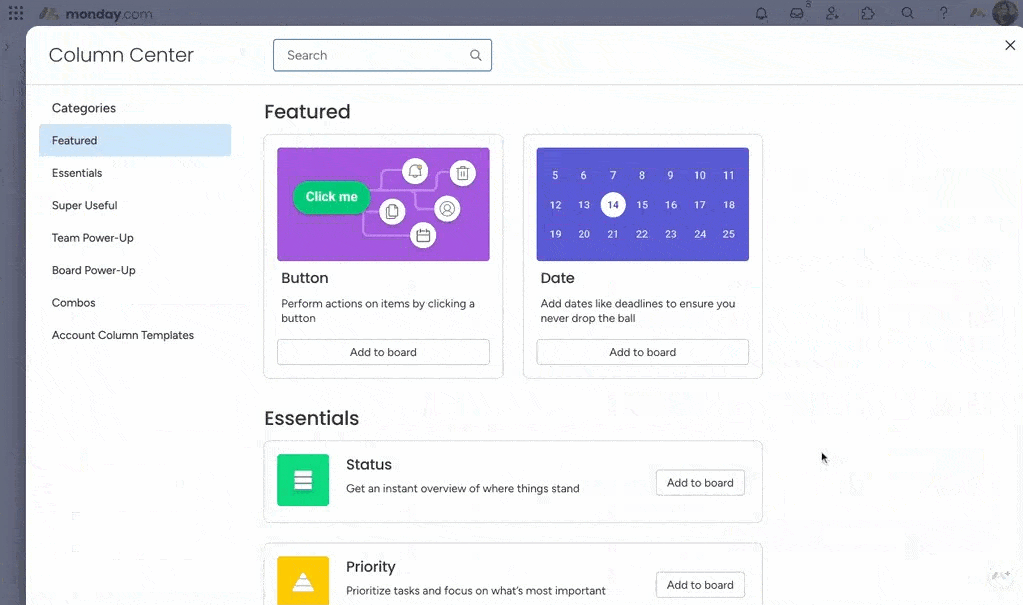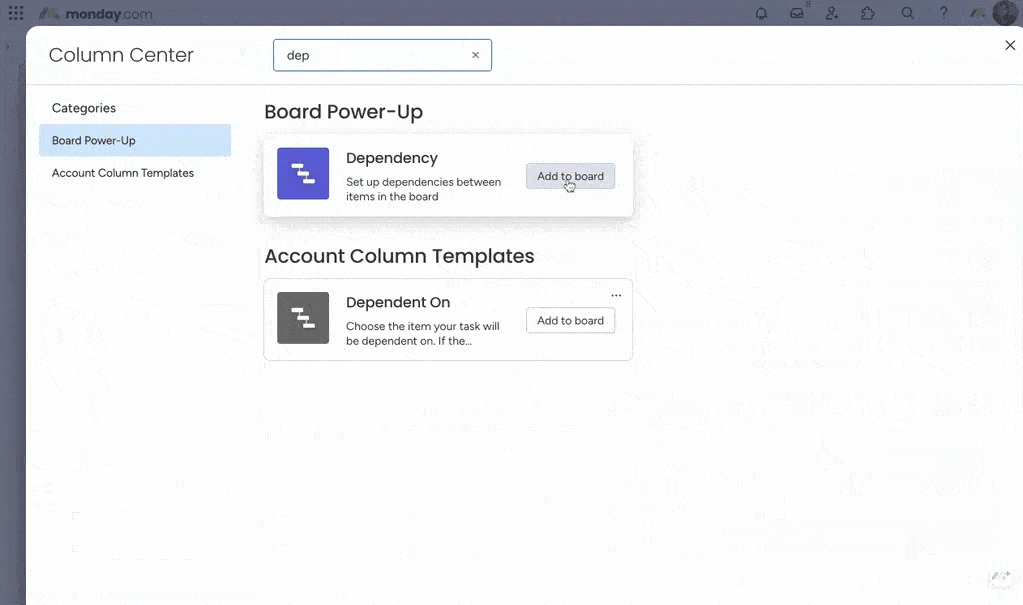
Dashboards aggregate open violations, review status, and resolution trends. Leaders gain a consolidated view of data quality efforts without relying on static reports.
Audit-ready collaboration
Conversations remain attached to each dependency item, preserving context and change history. This creates traceability for audits and long-term governance initiatives.
Building data integrity through functional dependencies
Functional dependencies define how information is structured and maintained across systems. When teams document, review, and monitor these relationships consistently, database models stay aligned with evolving business rules.
Begin with a review of existing tables to identify undocumented relationships. Then establish clear ownership and structured tracking so dependency definitions remain accurate over time.
Get StartedFAQs
What is the difference between full and partial functional dependency?
A full dependency requires the entire primary key to determine a non-key attribute. A partial dependency occurs when only part of a composite key determines a non-key attribute. Eliminating partial dependencies is required for Second Normal Form.
How do functional dependencies prevent data anomalies?
They define where each piece of information belongs. When data is stored in a single, authoritative location, updates, insertions, and deletions do not create inconsistencies.
Can functional dependencies exist in NoSQL databases?
Yes. The logical relationships still exist, but enforcement often happens at the application layer rather than through strict schema constraints.
What software can help track functional dependencies?
Data profiling tools can suggest dependencies. Teams often use structured workflow platforms such as monday work management to document rules, assign ownership, and track validation issues.
How often should dependencies be reviewed?
Review them during schema migrations, major business rule changes, and new data integrations. Quarterly audits help maintain alignment between technical design and operational needs.