
Projects rarely fail all at once. More often, things unravel gradually: deadlines slip, dependencies weaken, and small disruptions compound into major threats. A supplier exits unexpectedly, regulations change overnight, or a critical team member leaves midstream. Suddenly, well-crafted plans no longer hold.
Traditional risk management helps anticipate known issues, but it has limits. Contingency plans address specific risks, and backup systems protect data and infrastructure. When those safeguards fall short, organizations need a different layer of protection, one designed for moments when recovery matters more than optimization.
Fallback plans serve as that final safety net. They activate when primary strategies and standard mitigations can no longer sustain delivery, shifting focus from ideal outcomes to continuity and control. Rather than solving isolated problems, fallback plans stabilize operations during existential project threats.
In the sections below, we break down what fallback plans are, how they differ from other risk strategies, and why they are essential in 2026. The article explores practical frameworks, real-world examples, and modern approaches to building fallback plans that function under pressure, not just on paper.
Key takeaways
Fallback planning plays a critical role in helping teams stay operational when primary strategies break down. The points below summarize the core insights from this article and how organizations can build resilience into project execution.
- Fallback plans act as a final safety net: they activate only after primary plans and contingencies fail, prioritizing continuity and damage control over original project optimization.
- Clear activation triggers reduce decision paralysis: objective, measurable thresholds enable teams to shift into fallback mode quickly without hesitation or emotional bias during crises.
- Effective fallback plans focus on simplicity and speed: streamlined actions, defined roles, and minimal resource requirements increase the likelihood of successful execution under pressure.
- Fallback planning strengthens business continuity across industries: from technology and construction to finance and healthcare, these plans protect operations, compliance, and stakeholder trust when disruptions occur.
- Work management platforms enhance fallback execution: monday.com enables continuous risk monitoring, automated triggers, and coordinated responses that turn static fallback plans into dynamic, operational systems.
A fallback plan is a backup strategy that activates when both the primary plan and contingency measures fail. It represents the final safety net that keeps operations running when initial strategies can no longer deliver results.
Often referred to as Plan C, fallback planning addresses scenarios where known risks escalate into broader failure. The primary plan outlines the ideal path forward, while contingencies address anticipated disruptions. Fallback plans take effect when those safeguards are no longer sufficient.
While fallback plans vary by industry, they share a single objective: maintaining operational continuity under extreme conditions. Reviewing examples across sectors highlights how this approach supports resilience at scale.
Common fallback scenarios include:
- Software development: reverting to a previously stable release when a deployment causes system-wide outages.
- Construction management: reallocating crews to interior work when severe weather prevents outdoor progress.
- Marketing operations: shifting budget from an underperforming channel to paid search to protect quarterly targets.
Fallback plan meaning in project management
In project management, fallback plans define the fail-safe operating state. They shift the focus from achieving optimal outcomes to preserving value when delivery is at risk.
Within Agile environments, fallback planning may involve reducing scope to a Minimum Viable Product to meet a fixed deadline. In Waterfall projects, it can require replacing a vendor to ensure delivery of a core component. In both cases, success prioritizes continuity over optimization.
Fallback plans extend beyond contingency planning by addressing systemic failure rather than isolated risks. This distinction allows teams to respond decisively when standard mitigation approaches no longer apply.
When to activate your fallback option?
Effective fallback activation relies on objective criteria. During high-pressure situations, predefined thresholds remove ambiguity and support timely decision-making.
Activation triggers typically include:
- Budget overruns: costs exceeding an established percentage with less than half of planned deliverables completed.
- Critical resource loss: sudden unavailability of key personnel or systems that block the critical path.
- Regulatory changes: new compliance requirements that invalidate the current project scope.
- Technology failures: infrastructure outages that exceed maximum allowable downtime.
- Stakeholder withdrawal: loss of a primary sponsor or funding source essential to project viability.
Modern platforms like monday.com support this process through Portfolio Risk Insights, enabling teams to monitor risk signals in real time and respond without delay.
Key characteristics of successful fallback plans
High-performing fallback plans share a consistent set of characteristics that enable execution under pressure. These traits help teams act decisively when conditions deteriorate.
Successful fallback plans include:
- Simplicity: clear actions that reduce cognitive load during crisis situations.
- Resource efficiency: reliance on minimal inputs, reflecting constrained conditions.
- Speed of execution: rapid deployment without extended approval cycles.
- Measurable outcomes: defined success metrics focused on continuity and recovery.
- Stakeholder alignment: clearly assigned responsibilities understood across teams.
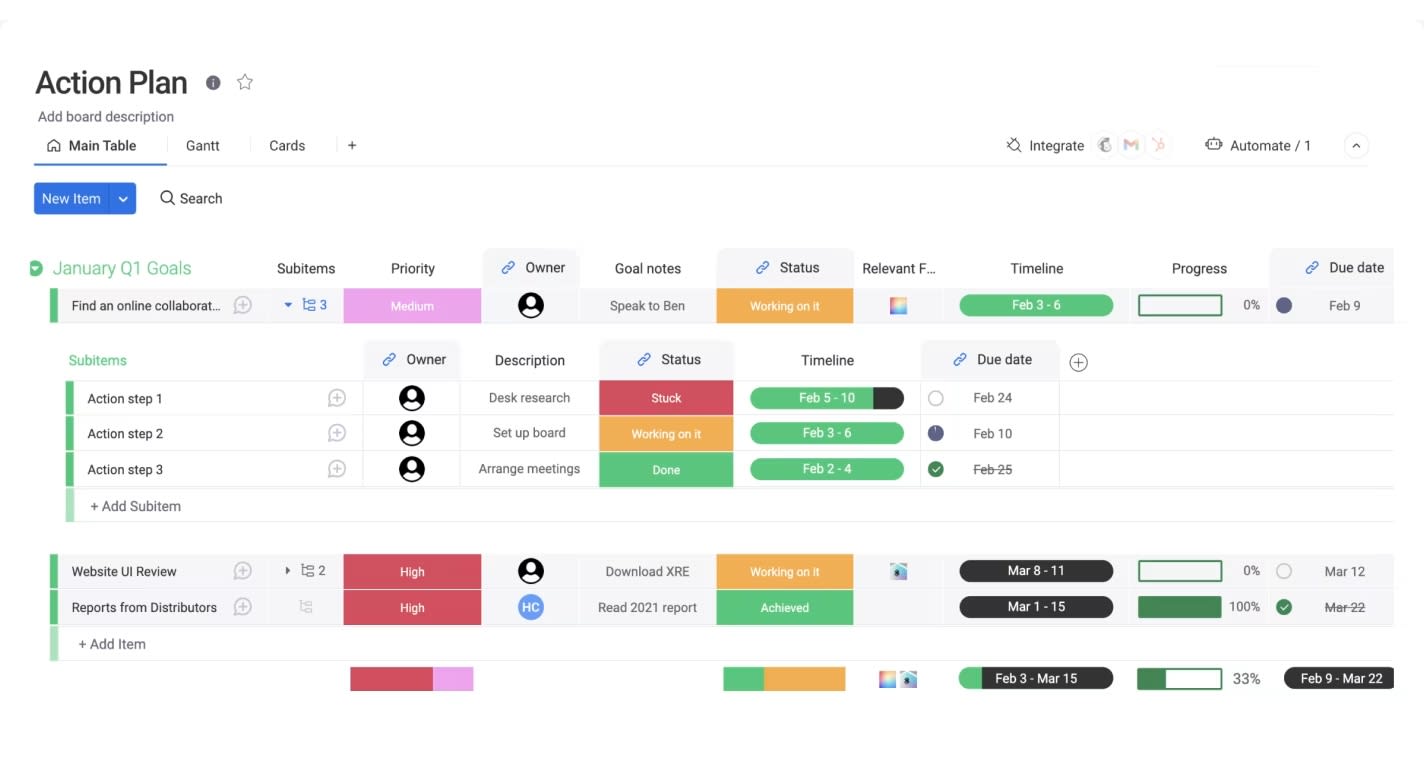
Fallback plan vs contingency plan vs backup plan
Although often used interchangeably, fallback plans, contingency plans, and backup plans serve distinct roles within risk management frameworks. Understanding these differences prevents gaps during escalation.
| Aspect | Contingency plan | Backup plan | Fallback plan |
|---|---|---|---|
| Timing | Proactive (planned for specific risks) | Preventive (continuous protection) | Reactive (activated after failure) |
| Scope | Specific, isolated risks | Data, systems, or resource protection | Comprehensive strategy failure |
| Activation | Predetermined specific triggers | Automatic or scheduled | Last resort "Plan C" |
| Resource requirements | Moderate (often budgeted) | Low (maintenance cost) | Minimal (survival mode) |
| Success definition | Maintain original objectives | Preserve assets/data | Minimize damage/continuity |
Understanding contingency plans
Contingency plans are proactive measures developed for identified risks with known probability and impact. They’re your “Plan B” options tailored to specific, anticipated scenarios developed during initial planning.
For example, supplier delays may be mitigated by pre-approved secondary vendors. The objective remains consistent delivery of original outcomes despite disruption.
The purpose of backup plans
Backup plans focus on preservation and recovery, not finding new ways to execute. They typically refer to data, system, or resource duplication.
A backup plan ensures that if a hard drive fails, the data exists elsewhere. If a generator dies, a secondary power source kicks in. Unlike fallback plans, backups don’t change how work gets done. They just restore the tools you need to keep going.
How fallback plans complete your risk strategy?
For example, supplier delays may be mitigated by pre-approved secondary vendors. The objective remains consistent delivery of original outcomes despite disruption.
Without this complete risk strategy, gaps emerge that can turn manageable setbacks into project cancellations. How confident are you that your organization has all three layers covered?
Why every project needs the fallback plan approach?
Fallback planning protects organizational investments and reputation during uncontrollable events. For leadership teams, it represents preparedness rather than pessimism.
These plans reinforce confidence among stakeholders by demonstrating that continuity remains achievable even under extreme conditions.
Protecting against residual risks
Residual risks are threats that remain even after all primary risk mitigation strategies are in place. No amount of planning kills every uncertainty in complex projects with multiple stakeholders.
Consider these realities:
- Regulatory landscapes shift overnight.
- Markets change unexpectedly.
- Force majeure events occur without warning.
Fallback planning provides structured responses to these residual risks. Platforms such as monday.com enable teams to track emerging threats across portfolios without manual oversight.
Ensuring business continuity
Project failure rarely happens alone. It cascades into operational disruptions, unhappy customers, and lost revenue. A fallback plan ensures critical business continuity even when specific projects encounter severe setbacks.
Instead of a website launch failure resulting in zero sales, a fallback plan keeps a legacy system operational to capture orders. Success means less downtime, steady customer service, and stakeholder trust that stays intact.
Meeting regulatory compliance standards
In regulated industries, fallback preparedness is a compliance requirement. Standards such as GDPR, SOX, and HIPAA expect organizations to demonstrate operational resilience.
Fallback plans support compliance by ensuring:
- Healthcare: patient safety protocols remain active during system outages.
- Finance: reporting accuracy is maintained even during software migrations.
- Manufacturing: quality standards continue despite equipment failures.

Effective fallback plans follow a consistent structure. These five components create a safety net teams can trust when everything else fails. Each component plays a role in fast, coordinated crisis response.
1. Activation triggers
Activation triggers are specific, measurable conditions that tell you exactly when to implement your fallback plan. Objectivity cuts through hesitation and emotional bargaining that slow down crisis response.
Triggers can be:
- Quantitative: budget variance exceeding 25%, timeline delay surpassing 30 days.
- Qualitative: regulatory prohibition, key partner withdrawal.
Automated monitoring tracks these triggers nonstop, no human error in detection.
2. Defined roles and responsibilities
Crises create confusion about who’s in charge. A fallback plan spells out roles that might look very different from normal operations.
Key roles include:
- Decision authority: who officially activates the plan?
- Resource manager: who reallocates assets?
- Stakeholder liaison: who manages communications?
The plan also names backup personnel for these roles, so you’re covered if key leaders aren’t available.
3. Resource allocation framework
Fallback plans usually run under tight constraints. The resource framework focuses on essential outcomes, not optimal results.
This part identifies the minimum resources you need to keep projects alive. It outlines how to:
- Secure emergency funding from contingency budgets.
- Access contingency resource pools across departments.
- Execute resource-sharing agreements with other teams.
4. Communication protocols
When you activate a fallback plan, information needs shift fast. You need rapid, accurate updates, not standard weekly reports.
This component establishes:
- Emergency communication channels with redundant pathways.
- Update frequency for different stakeholder groups.
- Pre-approved message templates for internal teams, executives, and external clients.
These protocols keep messaging consistent and stop rumors from eroding stakeholder confidence.
5. Performance metrics and monitoring
Success means something different when you’re in fallback mode. You stop optimizing and start controlling damage.
Instead of tracking “features delivered,” plans track:
- Time to recovery from initial failure.
- Business continuity maintenance across critical functions.
- Resource utilization efficiency under constrained conditions.
This sets up monitoring that shows you immediately whether the fallback is working or if you need to escalate further.
Creating a fallback plan turns vague anxiety about failure into a concrete strategy you can act on. These steps give you a framework to build safety nets for your most critical projects.
Step 1: map critical risks and dependencies
The foundation of a fallback plan is rigorous risk identification that looks beyond obvious threats. Teams use brainstorming sessions and dependency mapping to identify single points of failure and complex interdependencies.
This step involves:
- Risk categorization by impact and likelihood.
- Stakeholder input from technical, financial, and operational viewpoints.
- Dependency analysis to identify cascading failure points.
Step 2: establish trigger points and thresholds
Identified risks convert into specific, measurable trigger points. This step sets thresholds that provide early warnings without causing false alarms.
Effective triggers use:
- Leading indicators: budget burn rate trends, resource utilization patterns.
- Lagging indicators: missed milestones, quality metrics.
These thresholds are stress-tested through scenario planning to ensure they align with organizational risk tolerance.
Step 3: design alternative execution strategies
This phase develops realistic “Plan C” approaches. The goal is to achieve core objectives with reduced scope or alternative methods.
Strategies might include:
- Phased delivery approaches: breaking deliverables into smaller, manageable chunks.
- Outsourcing specific components: leveraging external expertise when internal resources fail.
- Technology substitution: replacing complex systems with simpler alternatives.
- Scope reduction: focusing on the absolute minimum viable product.
These alternatives are validated with key stakeholders to ensure they remain acceptable outcomes.
Step 4: allocate resources and ownership
A plan is only as good as the resources behind it. This step secures the necessary budget, personnel, and tools for the fallback strategy.
It identifies where resources will come from:
- Contingency budgets set aside for emergencies.
- Reallocation from other projects with lower priority.
- External partners with pre-negotiated agreements.
Teams using monday.com can leverage the Workload View to identify available capacity and assign ownership for every aspect of the plan.
Step 5: build communication workflows
Communication systems must withstand crisis pressure. This involves creating stakeholder communication matrices that define who needs to know what and when.
Key elements include:
- Message templates drafted for various scenarios to save time during actual events.
- Escalation procedures ensure critical issues reach decision-makers immediately.
- Backup communication channels when primary systems fail.
Step 6: test and refine your plans
A fallback plan is a living document requiring validation. Regular testing through tabletop exercises and simulation drills reveals gaps in logic or resource availability.
Testing involves:
- Quarterly tabletop exercises with key stakeholders.
- Simulation drills under realistic pressure conditions.
- Post-incident reviews of minor issues to refine the plan.
This ensures the plan evolves alongside the project and changing external conditions, maintaining its viability over time.
Fallback plan examples that drive results
Real-world examples demonstrate how fallback strategies preserve value across different contexts. These scenarios show how organizations respond when primary strategies fail, illustrating the practical application of fallback planning principles across various industries.
Technology and software development
In software development, fallback planning often protects service availability and delivery timelines. Consider a large-scale product launch that encounters unexpected server capacity constraints.
The fallback activates a cloud scaling protocol that provisions additional server capacity while temporarily disabling non-essential background features. User-facing services remain available, creating space to address the root issue without disruption.
In another scenario, a key developer exits midway through delivery. The fallback plan triggers a predefined knowledge transfer process, onboarding a pre-approved agency partner that can continue development using documentation prepared during earlier planning phases.
Construction and infrastructure
Physical constraints drive fallback planning in construction. When unseasonal heavy rains delay foundation pouring for a skyscraper, the site manager shifts the schedule to focus on off-site pre-fabrication of structural elements.
The project timeline compresses in later stages, but current workforce utilization remains high, preventing layoffs and remobilization costs. When a primary material supplier goes bankrupt, the procurement team activates agreements with secondary suppliers for alternative, pre-approved materials, accepting a slight cost increase to avoid work stoppage.
Financial services and banking
Compliance and data integrity are paramount in finance. When a core banking system upgrade fails data validation checks during migration, the team executes a rollback procedure, reverting to the legacy system within a four-hour window to ensure banking services open on time the next morning.
When merger integration faces regulatory hurdles, the integration team shifts to a federated operating model, keeping systems separate but connected via API, ensuring compliance while delaying full integration.
Healthcare systems
Patient safety dictates healthcare fallback strategies. When an Electronic Health Record system goes offline due to a cyberattack, the hospital reverts to established paper charting protocols.
Crash carts and pharmacy stations switch to manual override procedures. Patient care continues safely, with data entered retroactively once systems are restored.
Automating fallback plans with AI-powered solutions
Work management platforms have evolved fallback planning from static documents into dynamic, AI-driven systems. Automation enhances human judgment, making risk management proactive rather than purely reactive. This technological evolution transforms how organizations detect, respond to, and recover from project failures.
Predictive risk detection systems
AI systems identify potential risks long before they trigger crises. Machine learning algorithms analyze project data patterns to predict likely failure points:
- Communication lags between team members.
- Subtle shifts in resource utilization patterns.
- Slowing task completion rates across project phases.
Portfolio Risk Insights on monday.com categorizes and prioritizes these risks automatically, alerting leadership to at-risk projects that appear healthy on the surface but show underlying instability.
Automated workflow transitions
Automation handles the chaotic transition from primary plans to fallback procedures. When specific trigger conditions are met, the platform automatically initiates fallback protocols.
This includes:
- Reassigning work to backup personnel.
- Updating project timelines based on new constraints.
- Reallocating budget line items without manual data entry.
AI Blocks automate the administrative burden of these transitions, ensuring teams focus on execution rather than paperwork.
Instant stakeholder alert networks
Automated communication systems ensure rapid, consistent notification. Intelligent notification systems customize messages for different stakeholder groups:
- Executives receive high-level impact summaries.
- Technical teams receive detailed action logs.
- External partners get relevant updates without sensitive information.
These systems escalate alerts if responses aren’t received within set timeframes and maintain permanent audit logs of all communications for compliance purposes.
Enterprise portfolio monitoring
AI-powered monitoring oversees the entire project portfolio simultaneously. It identifies risks that only become visible at the aggregate level, such as resource conflicts where five different fallback plans rely on the same emergency engineering team.
Organizations gain executive visibility into organizational risk exposure, allowing for portfolio-level resource optimization and ensuring fallback strategies remain viable even when multiple projects face concurrent challenges.
Eight ways to ensure fallback plan success
Successful fallback plans rely on advanced best practices derived from real-world implementations. These strategies separate robust safety nets from theoretical documents that fail under pressure. Each practice addresses specific failure points that organizations commonly encounter during crisis execution.
Keep plans simple and actionable
Complexity causes failure during crises. Stress reduces cognitive capacity, making complex decision trees difficult to navigate.
Effective plans:
- Distill procedures into essential actions using direct language.
- Use visual aids to communicate key steps quickly.
- Remove non-critical elements that don’t directly support survival.
Ensure every step is critical for survival and directly supports business continuity.
Schedule regular testing cycles
Plans must be tested to ensure viability. This involves quarterly tabletop exercises, simulation drills, or partial activations.
Testing schedules:
- Minimize disruption while ensuring readiness.
- Evaluate results to identify gaps.
- Ensure teams know the plan works before real emergencies occur.
Maintain redundant communication channels
Communication infrastructure must function when other systems fail. Redundant channels ensure connectivity when primary systems go down.
Examples include:
- WhatsApp groups if Slack fails.
- Phone trees if email systems crash.
- Physical meeting points if digital communication fails entirely.
Contact information updates automatically, and systems are stress-tested to handle increased crisis volume.
Plan for resource flexibility
Resource allocation systems must adapt quickly. This involves:
- Maintaining resource pools for emergency deployment.
- Establishing pre-signed sharing agreements between departments.
- Creating flexible frameworks allowing rapid reassignment.
The balance between efficiency and emergency availability is actively managed.
Document lessons learned
Every test and activation provides data. Post-incident reviews capture these insights, documenting what worked and what didn’t.
These lessons:
- Incorporate into future planning cycles.
- Share across teams to raise organizational baseline.
- Create institutional memory that survives personnel changes.
Update plans with changing conditions
Plans must evolve with projects. Updates occur whenever significant changes happen to scope, resources, or external conditions.
A schedule ensures plans are:
- Reviewed quarterly at minimum.
- Updated immediately after major project changes.
- Kept relevant and actionable as conditions shift.
Train teams on execution procedures
Teams need muscle memory for crisis response. Training goes beyond reading documents, it involves active practice of roles and responsibilities.
Cross-training ensures:
- Primary role holders know their responsibilities.
- Backup personnel can step in immediately.
- Everyone understands the activation process.
Measure and report on effectiveness
Metrics demonstrate the value of fallback plans. KPIs such as activation speed, recovery time, and stakeholder satisfaction quantify the plan’s impact.
Reporting systems provide executives with visibility into:
- How well the organization manages risk?
- ROI justification for investment in preparedness.
- Areas for improvement in future planning cycles.
“monday.com has been a life-changer. It gives us transparency, accountability, and a centralized place to manage projects across the globe".
Kendra Seier | Project Manager“monday.com is the link that holds our business together — connecting our support office and stores with the visibility to move fast, stay consistent, and understand the impact on revenue.”
Duncan McHugh | Chief Operations OfficerBuild resilient operations with monday.com
Teams managing complex projects face growing pressure from fragmented tools, delayed risk visibility, and manual escalation processes that slow response when disruptions occur. When issues compound, workflows break down, decisions stall, and the gap between daily execution and strategic goals becomes harder to bridge.
monday.com addresses these challenges by embedding fallback planning directly into how work gets done, enabling teams to detect risk earlier, act faster, and stay aligned when plans change.
Key benefits include:
- Continuous risk visibility: real-time portfolio insights surface emerging threats before they escalate into failures.
- Automated fallback activation: predefined triggers initiate workflows instantly, reducing response time and decision paralysis.
- Centralized coordination: tasks, resources, and communications stay connected in a single source of truth.
- Adaptive resource management: teams reallocate capacity quickly to protect critical outcomes under constrained conditions.
- Measurable recovery performance: dashboards track continuity, recovery speed, and impact as fallback plans execute.
By turning fallback planning into an operational capability rather than a static document, organizations gain efficiency, alignment, and resilience at scale, responding to disruption with clarity and maintaining strategic momentum without adding complexity.
Frequently asked questions
Can you use one fallback plan for multiple projects?
While high-level frameworks and templates can be shared across projects, each project requires a customized fallback plan addressing its specific risks, stakeholders, and resource constraints. Generic plans often fail to account for unique project dependencies.
Who should own fallback plan maintenance?
Ownership typically resides with the project manager or designated risk coordinator, supported by input from key stakeholders and subject matter experts. Clear ownership ensures plans stay current and actionable.
How do you measure fallback plan ROI?
ROI is measured by costs avoided (downtime, penalties, lost revenue) and value preserved (customer trust, brand reputation) when the plan is activated. Track metrics like recovery time, stakeholder satisfaction, and prevented losses.
Should you share fallback plans with clients and vendors?
Sharing relevant sections of fallback plans with external partners builds confidence and improves coordination, but sensitive internal data regarding capabilities or alternative suppliers should be redacted. Transparency about preparedness strengthens partnerships.